Announcing Mirroring Azure SQL Database in Fabric for Public Preview



In the era of digital transformation, advanced analytics and an AI driven world, data has emerged as the new oil, powering businesses, and driving decision-making. But what good is this oil if it’s not refined and ready for use when needed? Moreover, managing, and ingesting data into a central platform for analytics and AI is costly and cumbersome process. This is where the importance of near-real-time data replication comes into play. It’s not just about having data; it’s about having the right data at the right time. To address these challenges, we launched Mirroring in Microsoft Fabric at Ignite’23 for private preview.
Today, we are excited to announce the public preview of Mirroring Azure SQL Database, Azure Cosmos Database and Snowflake data sources in Fabric, a new, simple, and frictionless way to replicate a snapshot of these source database in Fabric OneLake in Delta tables that keeps the data in sync in near-real time. The key benefits that Mirroring databases in Fabric enables are:
- Reduced total cost of ownership with zero compute to replicate along with generous amounts (terabytes) of storage based on the capacity size.
- Zero code with zero ETL
- Faster time to operational data, information to derive insights.
This blog will explore the importance of Mirroring Azure SQL database in Fabric, discuss its main features and how it can transform your data strategy.
How does Mirroring Azure SQL Database in Fabric work?
Mirroring Azure SQL Database in Fabric ensures that your source transactional SQL database is always up to date and available in the Fabric OneLake, providing a solid foundation for reporting, advanced analytics, AI, and data science. There is no complex setup or ETL for Mirroring. You setup the mirror from Fabric Data Warehousing experience by providing the Azure SQL server and database connection details, provide selections on what needs mirrored into Fabric, either all data or user selected eligible mirrored tables. And, just like that mirroring is ready to go.
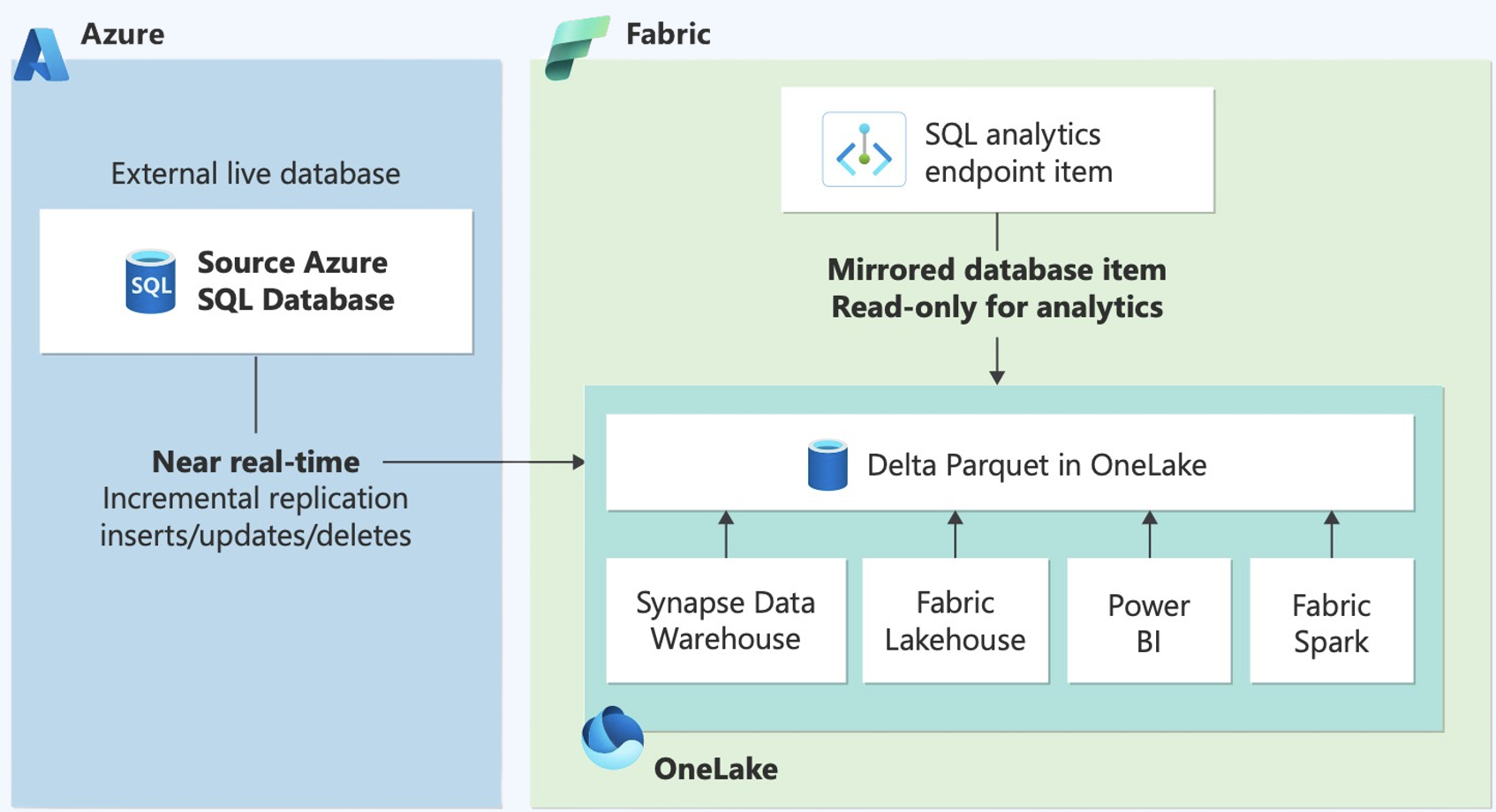
Mirroring Azure SQL database creates an initial snapshot in Fabric OneLake after which data is kept in sync in near-real time with every transaction when a new table is created/dropped, or data gets updated.
Key features
Mirroring for Azure SQL Database is built on the SQL’s Change Data Capture (CDC) stack optimized for lake-centric architecture. CDC stores changes locally in the database whereas Mirroring reads data from the harvested database transaction log and publishes the change data to OneLake storage. This change data is transformed into appropriate delta tables landing into Fabric OneLake. Moreover, DDL’s like add/drop column, alter table column <<datatype>>, drop table, rename table and rename column are also supported on actively mirrored tables.
As a SQL database administrator or user, you can also check the status of Mirroring by using these public stored procedure and dynamic management views:
- To confirm if Mirroring configuration of the Azure SQL database is enabled correctly, execute the following public stored procedure. The key columns to look for here are the “table_name” and “state”. Any value of “state” column besides “4” indicates a potential problem.
- exec sp_help_change_feed;
- If you’re experiencing mirroring problems, perform the following database level checks using Dynamic Management Views (DMVs) if data changes flow properly:
- SELECT * FROM sys.dm_change_feed_log_scan_sessions;
- If the DMV above doesn’t show any progress on processing incremental changes, execute the below query to check if there are any problems reported:
- SELECT * FROM sys.dm_change_feed_errors;
The Mirrored data can also be actively monitored from Fabric providing more insights into mirroring operations and when was mirrored data last refreshed.
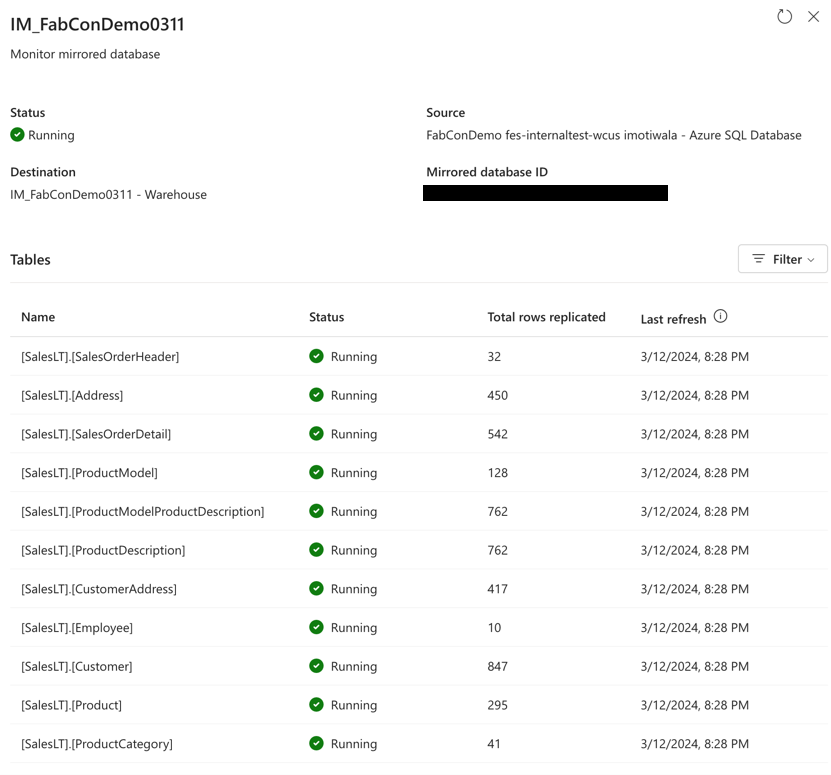
From here on, the mirrored data in the delta format is ready for immediate consumption across all Fabric experiences and features like Power BI with new Direct Lake mode, Data Warehouse, Data Engineering, Lakehouse, KQL Database, Notebooks and co-pilots work instantly.
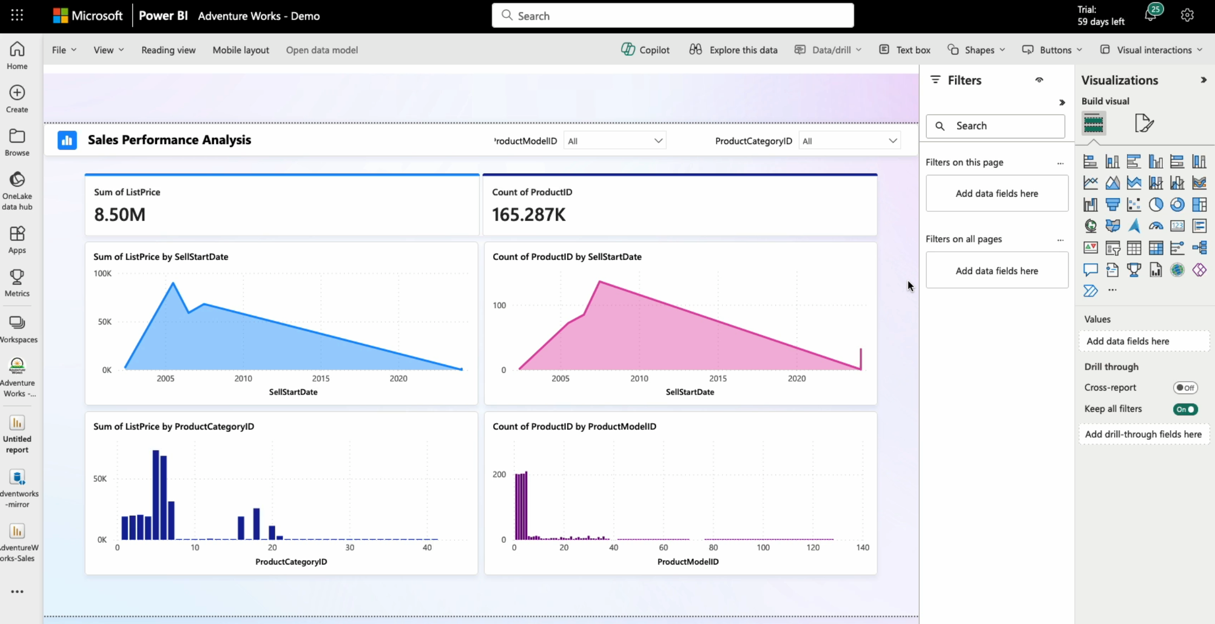
Power BI Direct Lake mode
Direct Lake mode is a fast path to load the data from the lake with groundbreaking semantic model capability for analyzing very large data volumes in Power BI. As Direct Lake mode also supports reading Delta tables right from OneLake, the Mirrored SQL database is Power BI ready along with Copilot.
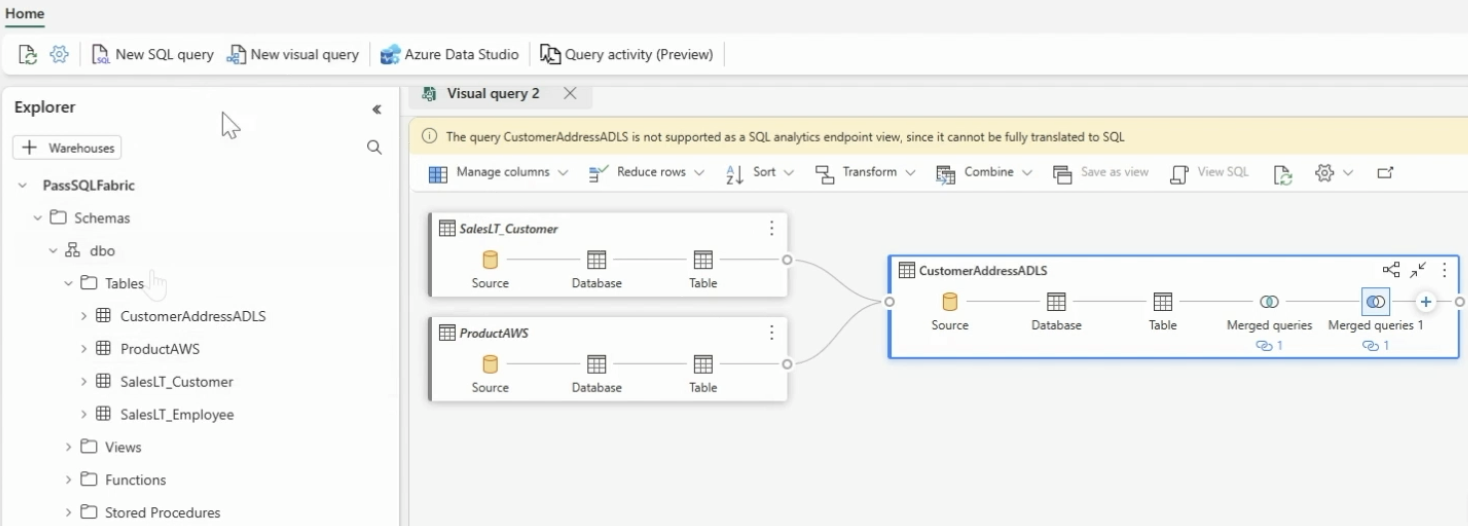
Cross-join Mirrored SQL Databases, Lakehouse’s, Warehouses
Data across any mirrored database (either Azure SQL DB, Azure Cosmos DB or Snowflake) can be cross joined as well enabling querying across any database, warehouse or lakehouse (either as a shortcut to AWS S3 or ADLS Gen 2 etc.)
Explore Data Science and Data engineering insights
Data scientists and data engineers can work with the mirrored SQL data that are created as shortcuts in Lakehouse.
Summary & get started.
To summarize, Mirroring Azure SQL Database in Fabric plays a crucial role in enabling analytics and driving insights from data by:
- Timeliness of Insights: Ensures that the most recent data is available for analysis. This allows businesses to make decisions based on the most current situation, rather than relying on outdated information.
- Improved Accuracy: The risk of discrepancies between the source and the replicated data is significantly reduced leading to more accurate analytics and reliable insights.
- Predictive Analytics and AI: Essential for predictive analytics and AI models that require the most recent data to make accurate predictions and decisions.
To get started and learn more about Mirroring Azure SQL in Fabric, its pre-requisites, setup, FAQ’s, current limitations, and tutorial, click here to read all about it. We hope you enjoy using Mirroring Azure SQL Database in Fabric and we look forward to hearing your feedback and questions. Please stay tuned for more updates and new features coming soon.

