Use Semantic Kernel with Lakehouse in Microsoft Fabric




Microsoft Fabric allows enterprises to bind different data sources through OneLake, and data engineer can call a unified API for different business scenarios to complete data analysis and data science. This article will describe how to allow data scientists to use Semantic Kernel with Lakehouse in Microsoft Fabric
In Microsoft Build 2023, Microsoft proposed the concept of Copilot Stack, and clarified the important steps and methods when we use LLM to build applications. We can use Microsoft’s open source Semantic Kernel to implement applications based on the concept of Copilot Stack. Semantic Kernel is better maintain the connection between Prompt and traditional code. We can quickly build Copilot apps with Semantic Kernel 
Enterprises are used to storing unstructured documents on Azure Blob Storage. We can connect documents that require QA on Azure Blob Storage and related prompts through Lakehouse of Microsoft Fabric. Microsoft Fabric‘s Lakehouse is a data architecture platform for storing, managing, and analyzing structured and unstructured data in a unified location. Store documents and related prompts through Lakehouse and then use Semantic Kernel to complete the prototype design of Copilot applications
Let’s link the documents in Azure Blob Storage with LakeHouse firstly
PS: Please upload Prompt and Docs to Azure Blob Storage before to run this sample
- Go to Microsoft Fabric Portal (https://app.fabric.microsoft.com/) , Select ‘Data Engineering’
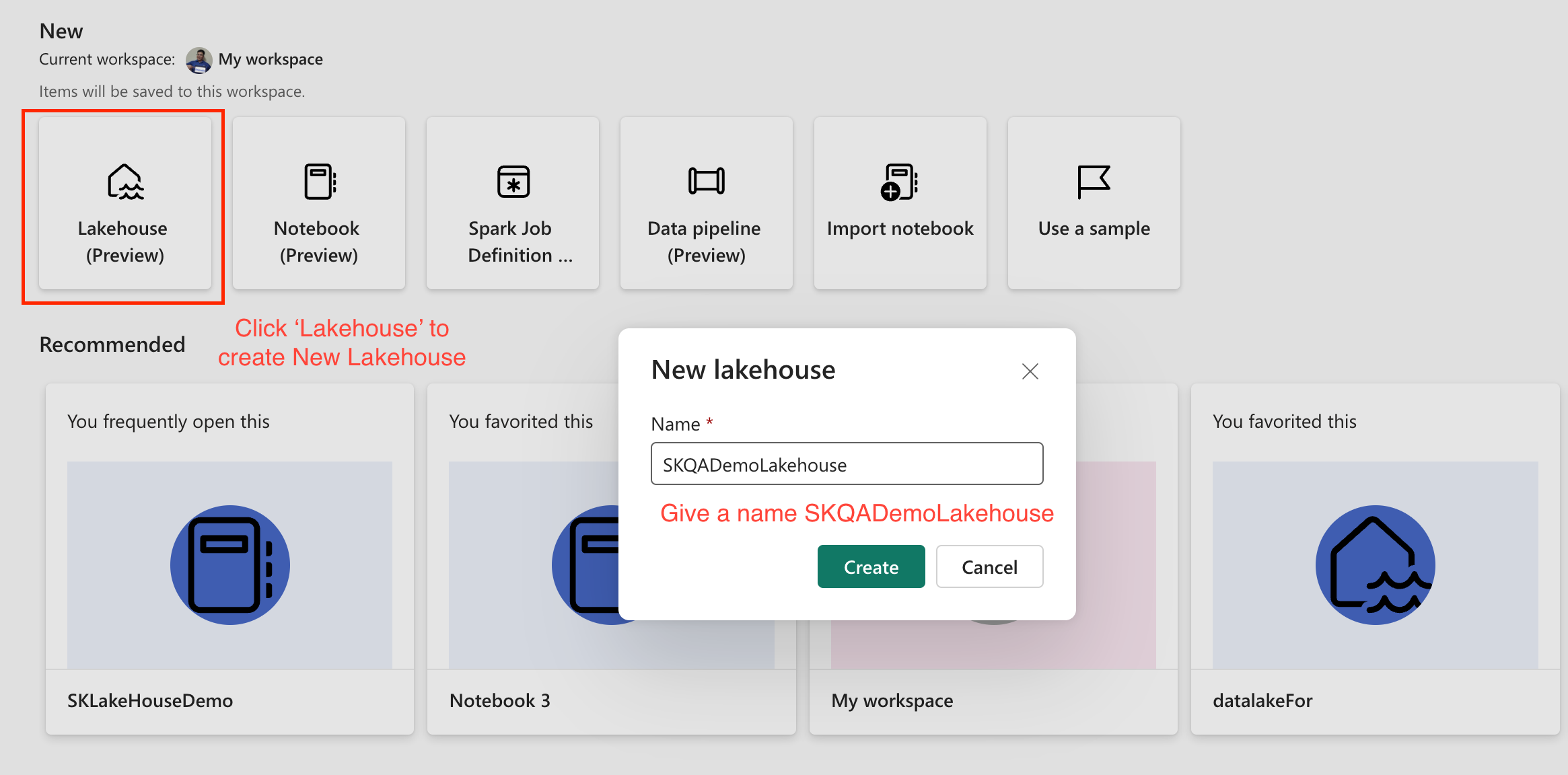
- Create New Lakehouse, Give a name ‘SKQALakeHouse’
- In Lakehouse portal, Select ‘New Data Pipeline’

Give a name ‘SKAzureBlobPipeline’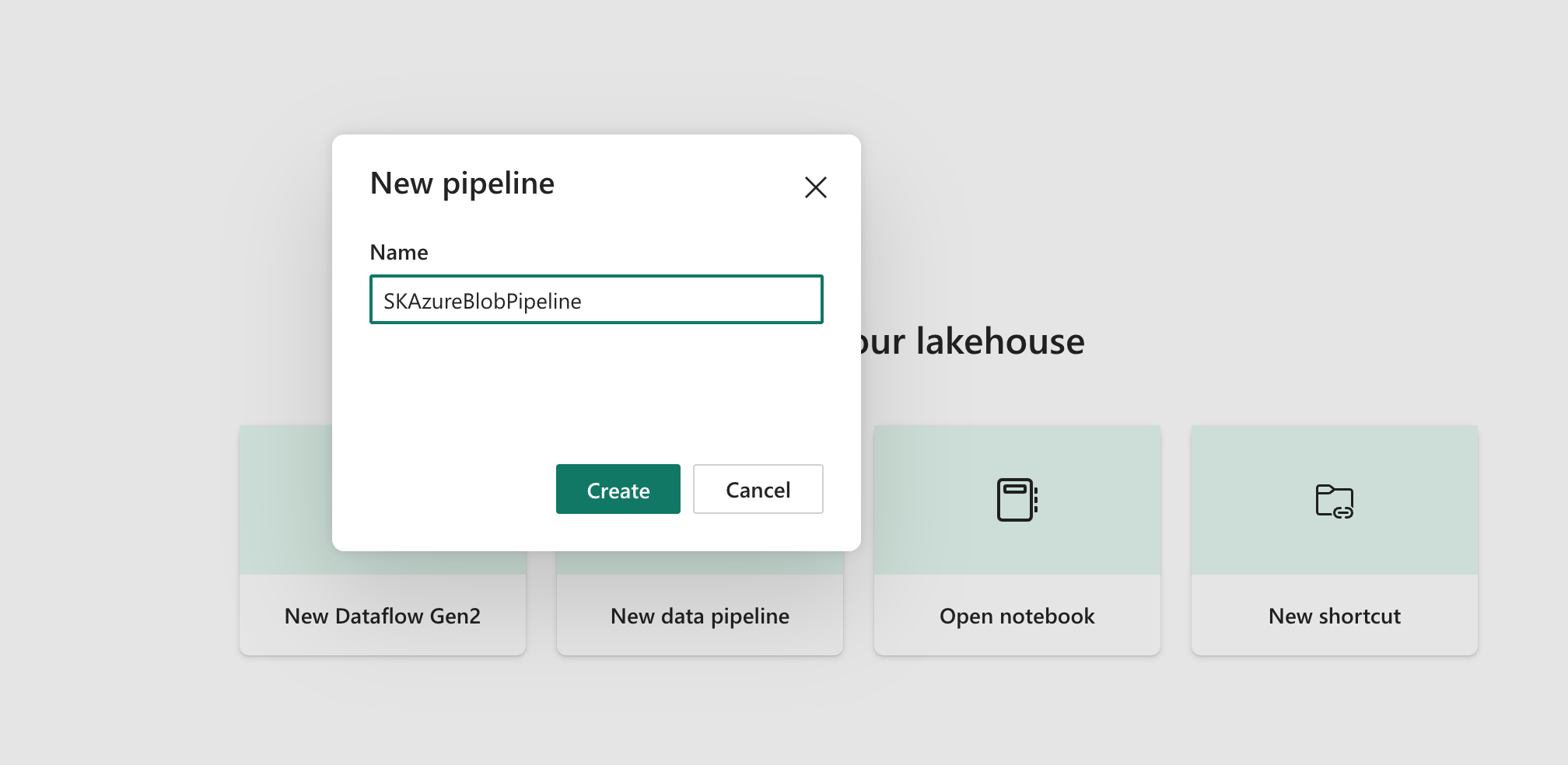
- Copy Azure Blob Storage Data to Lakehouse
choose Azure Blob Storage as your data source
Get your Azure Blob Storage account name in Azure Portal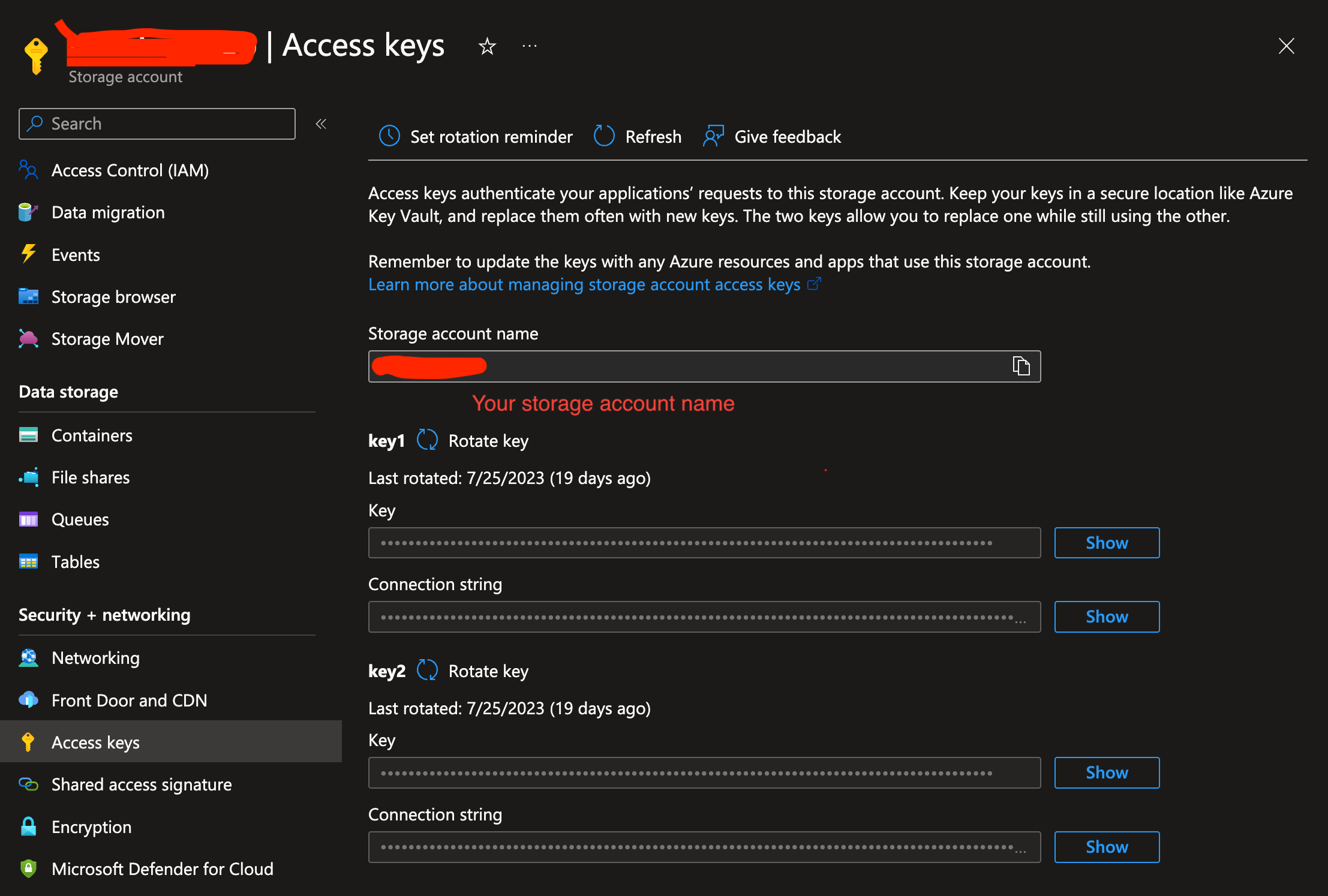
Select ‘Create new connection‘, you can insert URL like https://{Your blob storage account name}.blob.core.windows.net/{Your blob storage container}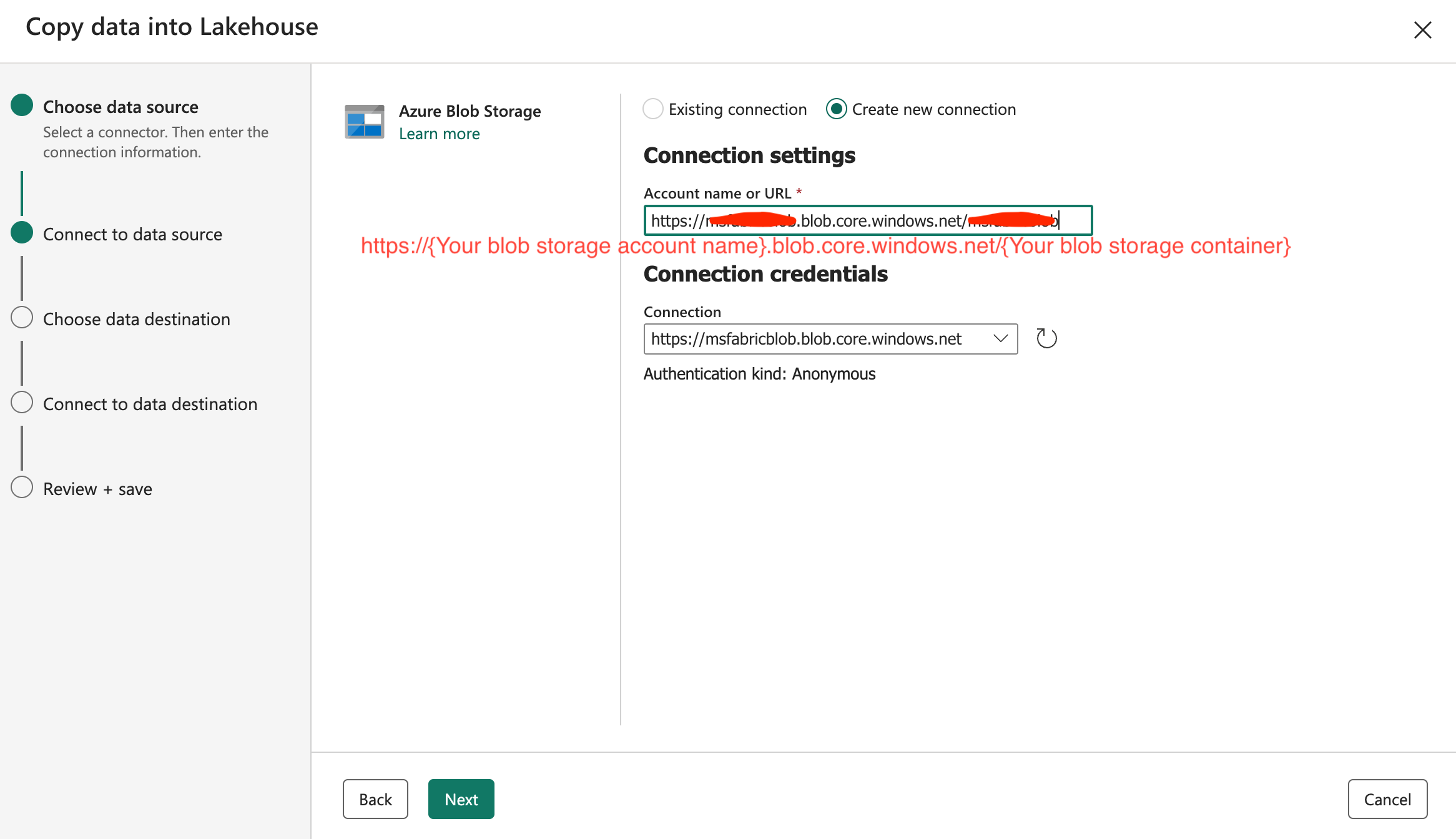
If your URL is Okay, the result is as follows
Choose ‘msfabricblob'(Your container name), and ‘Select your binary copy’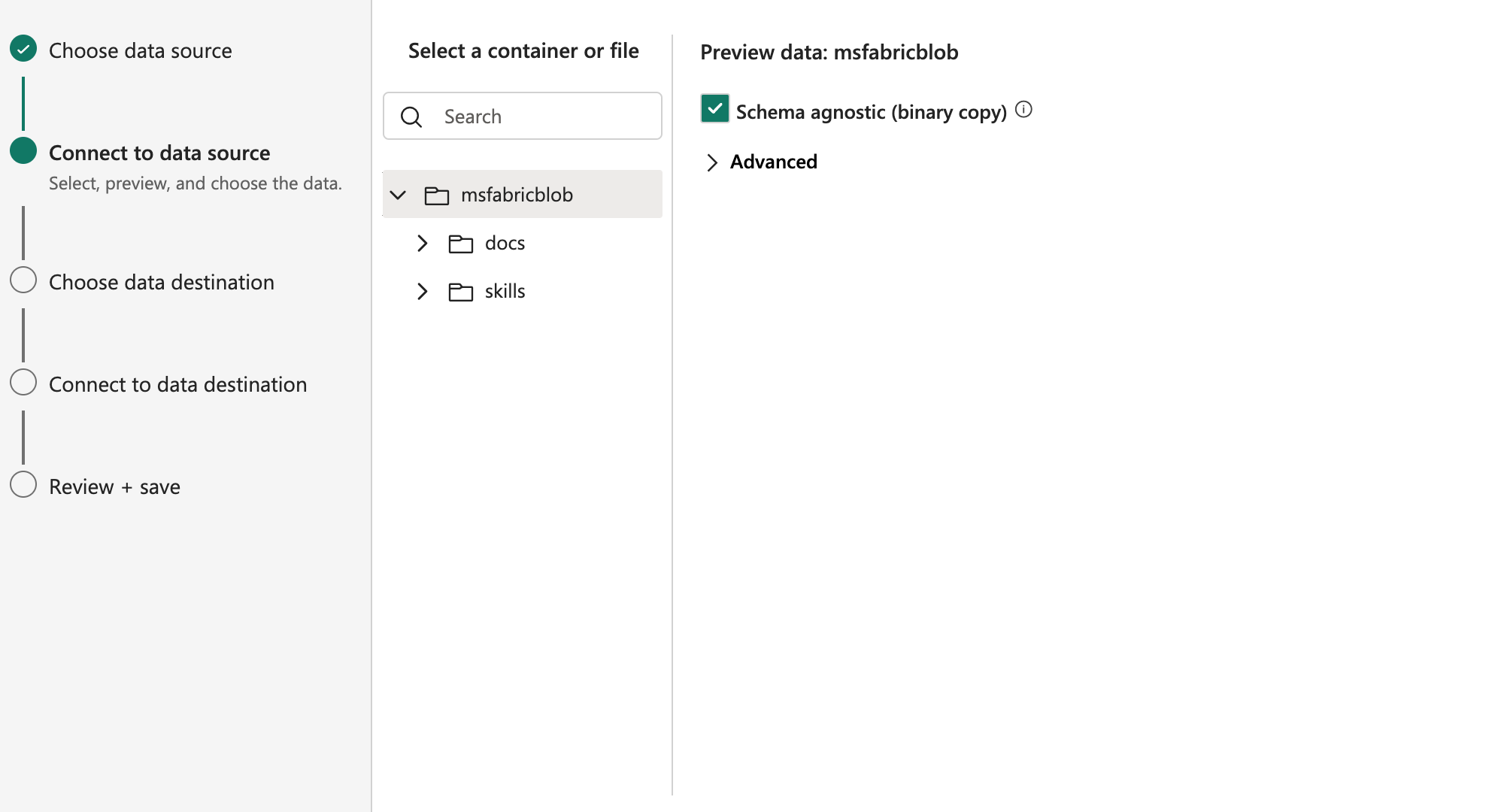
Set data destination choose ‘Files’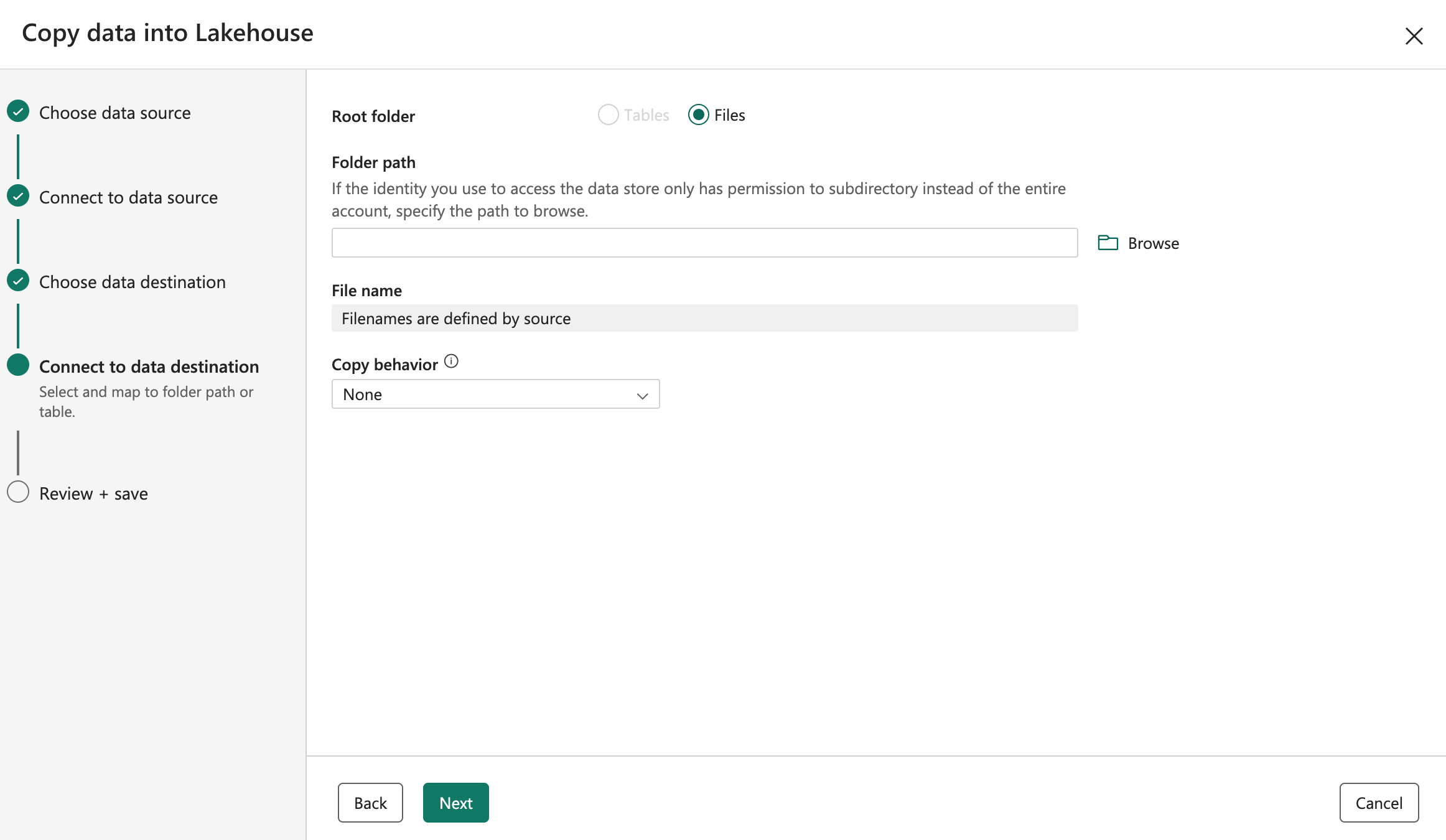
Save, All is done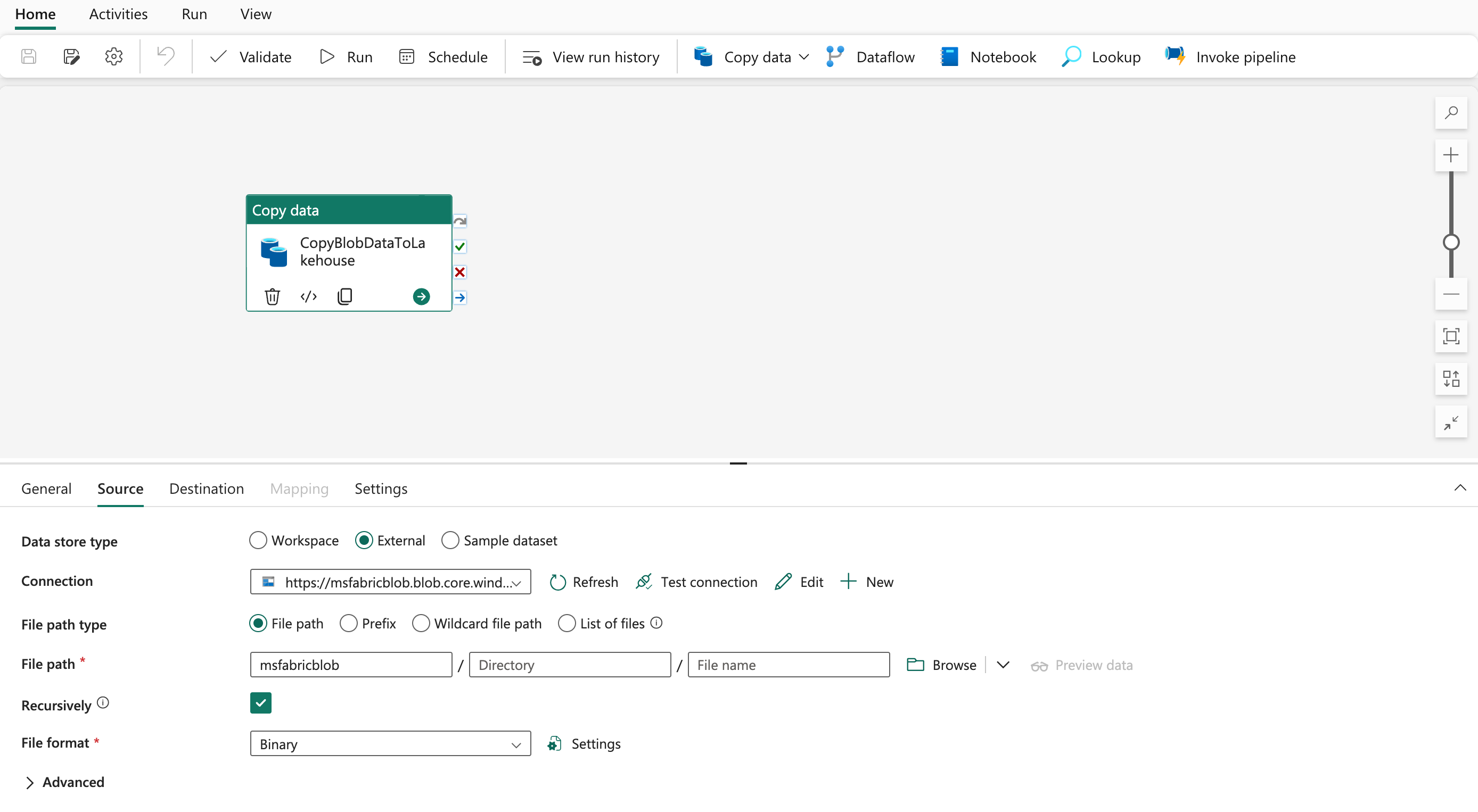
- Choose ‘SKQADemoLakehouse’ to confirm azure blob storage import to Lakehouse
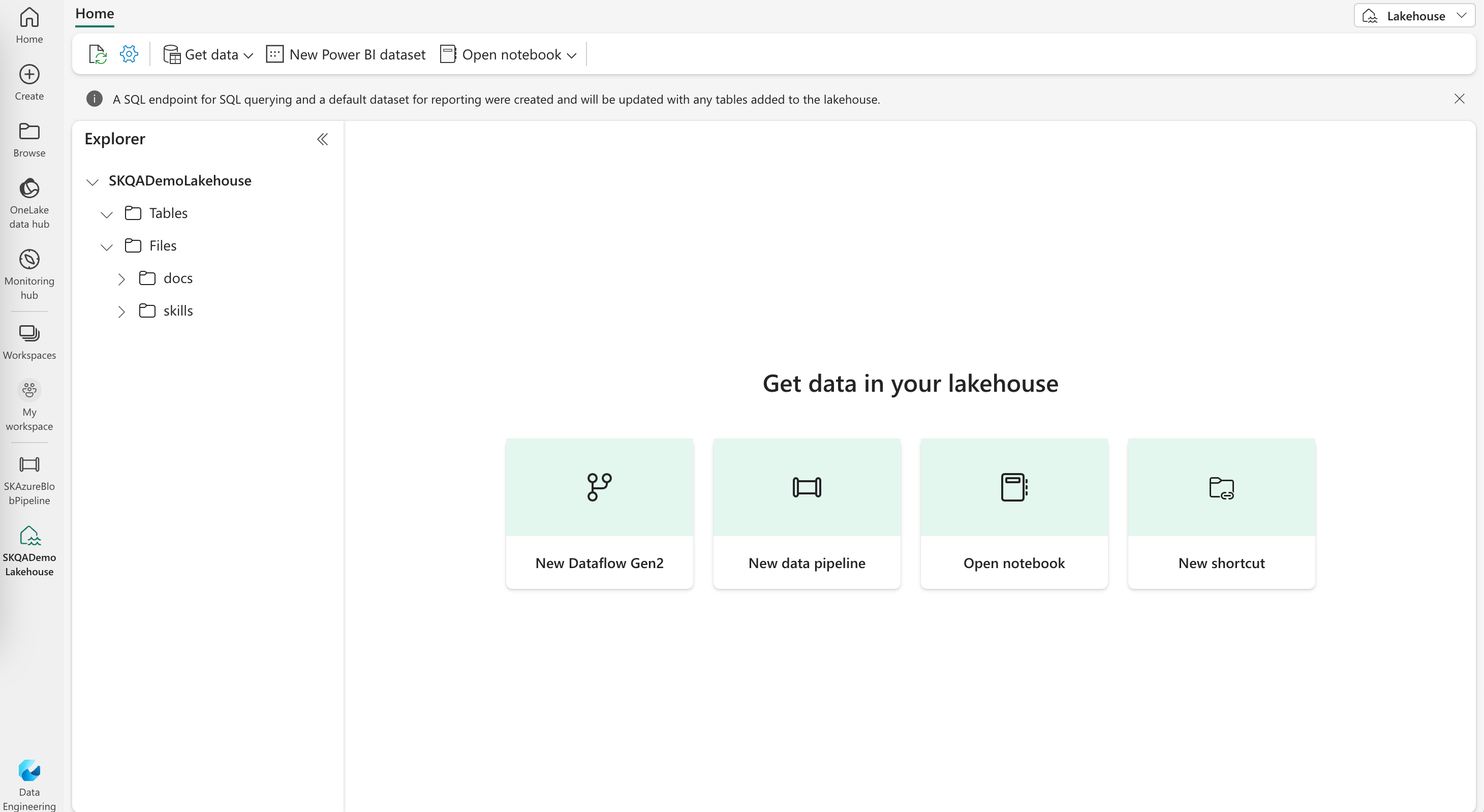












When Lakehouse is successfully built, we can write related Notebooks in Microsoft Fabric through the role of data science
- Choose Data Science
- Create New Notebook
Add ‘SKQADemoLakehouse’ to Notebook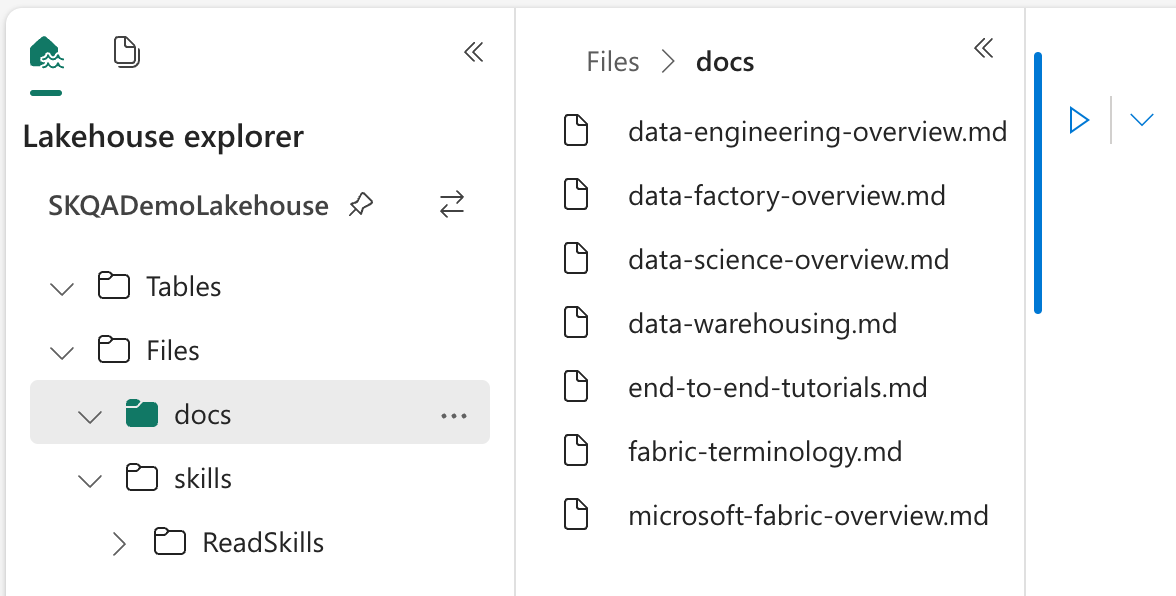
- Go to Notebook , Select ‘PySpark(Python)’

- Edit your notebooks, We use Semantic Kernel to do a knowledge extraction
# Install Semantic Kernel SDK
# Import Library
# Init Your Azure OpenAI Settings
PS: To run this example, use gpt-3.5-turbo-16k on Azure OpenAI Service
# Set Semantic Kernel Configuration
Use Semantic Kernel to read the Lakehouse path, such as the path of Skills in ‘/lakehouse/default/Files/skills’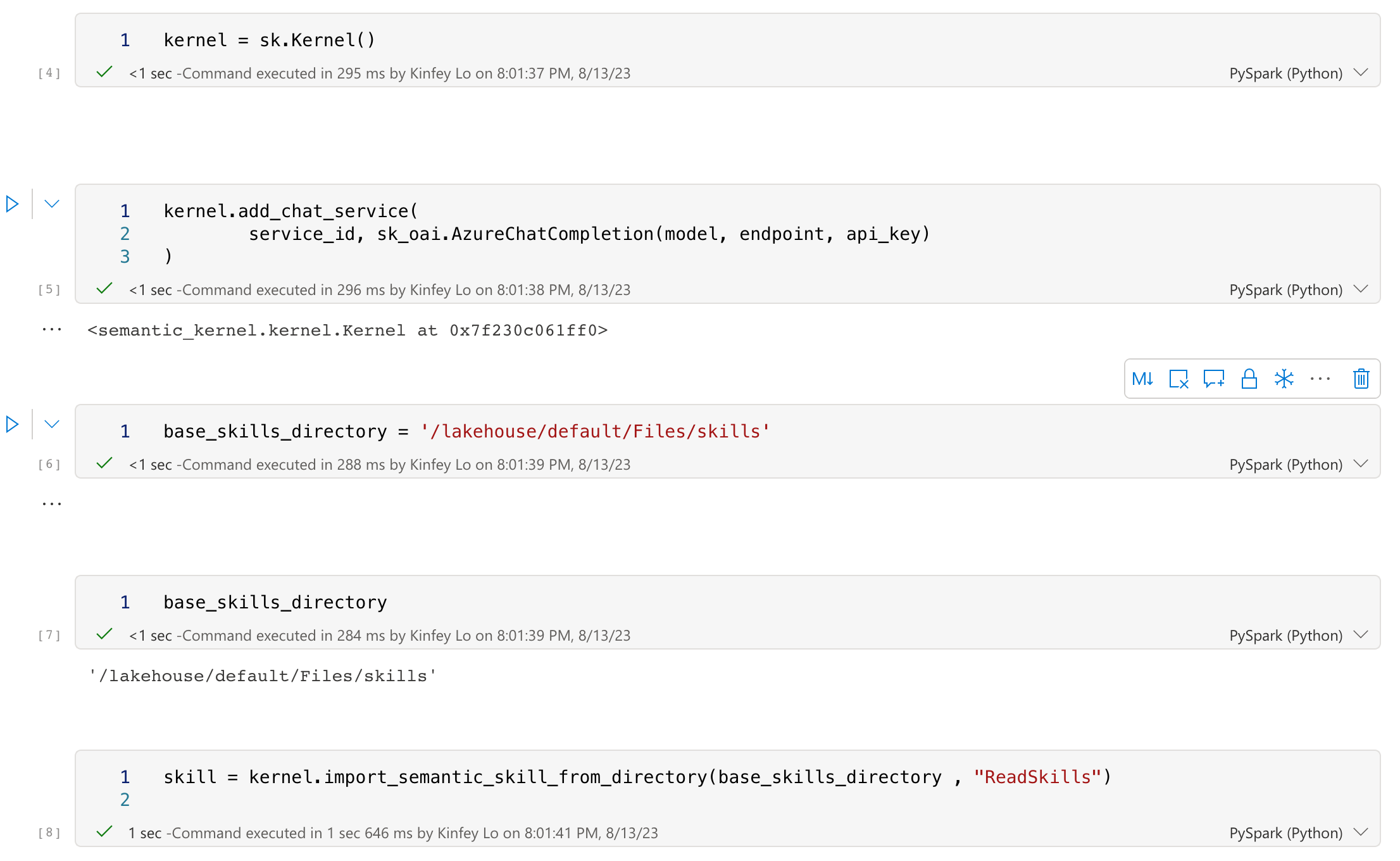
# Read docs with Semantic Kernel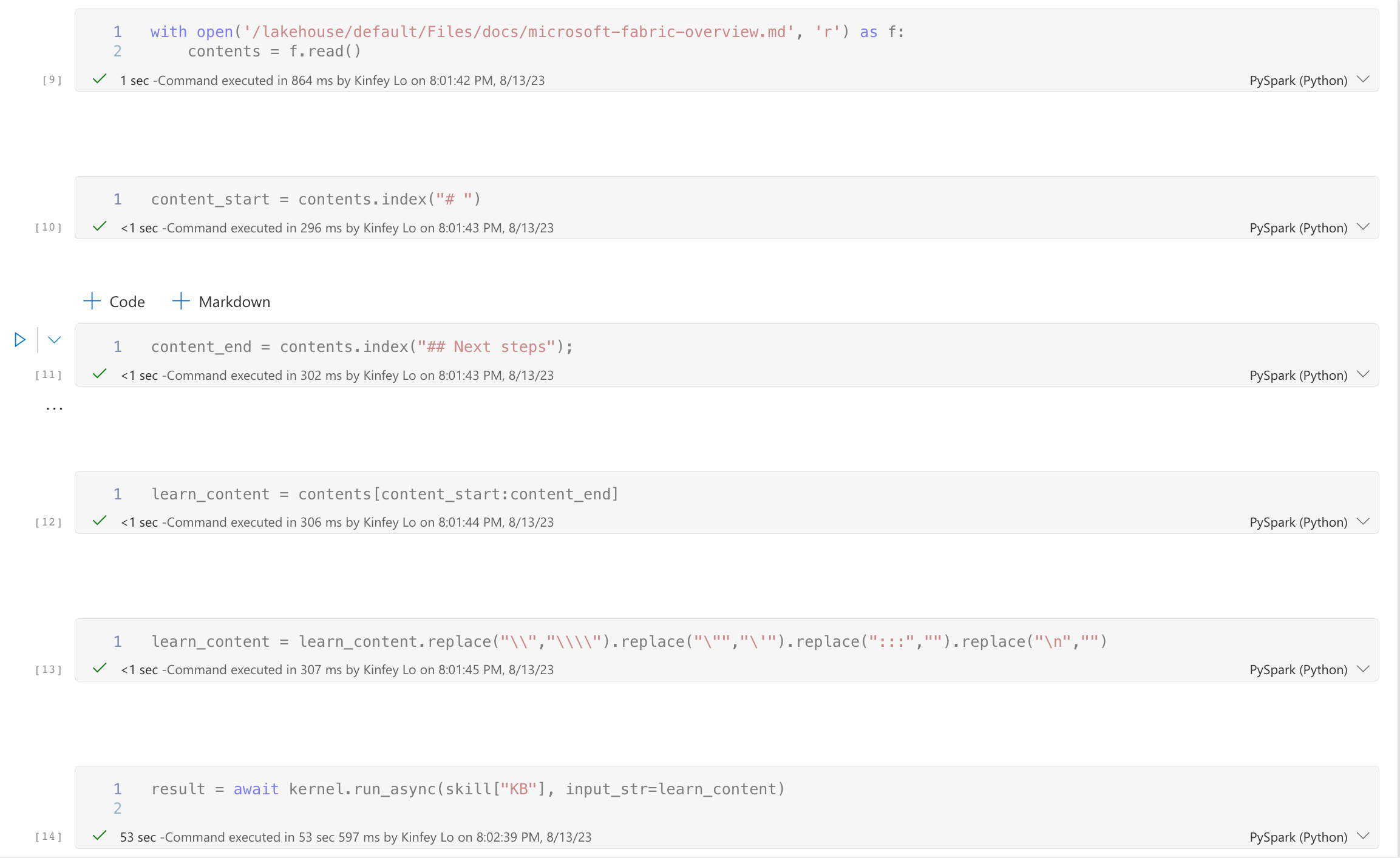
# Get the result in JSON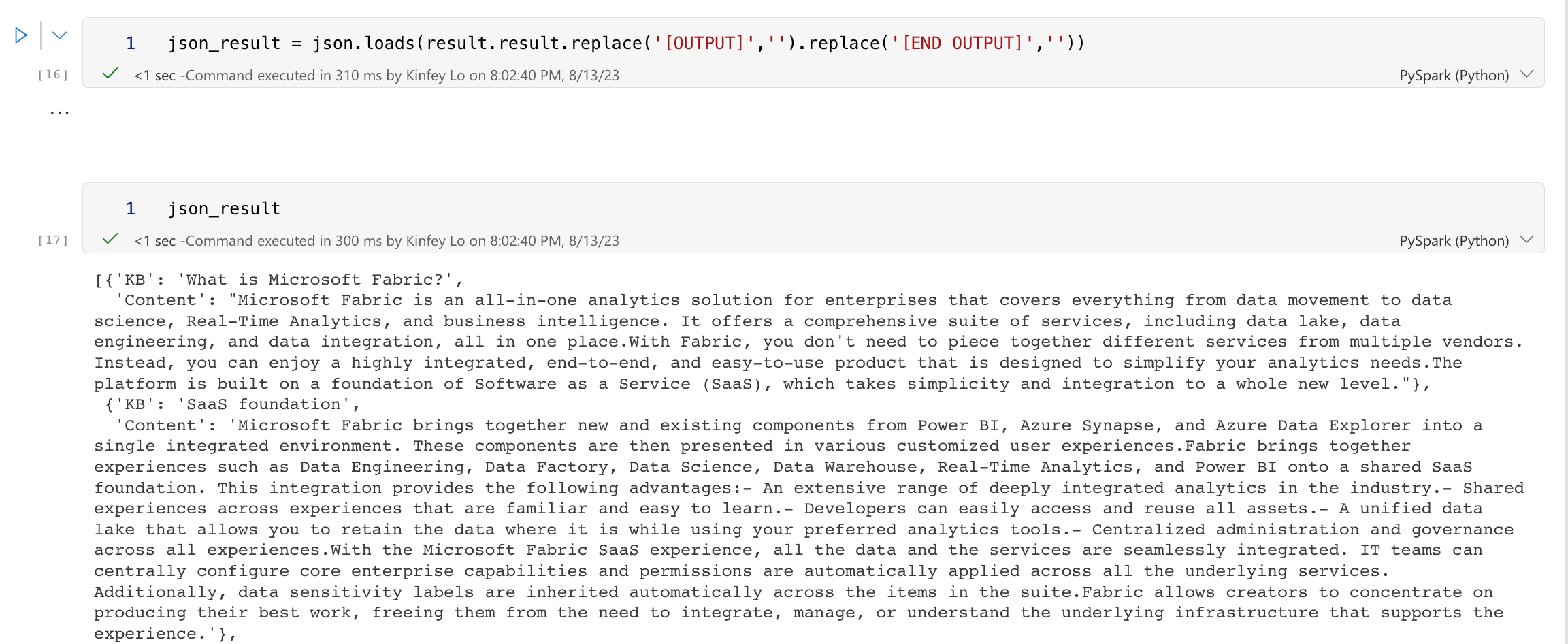
You have taken the first step to integrate the Semantic Kernel into the Microsoft Fabric scenario. Make Copilot’s application better combined with your enterprise big data scenarios to complete more intelligent work.











