Lakehouse vs Data Warehouse vs Real-Time Analytics/KQL Database: Deep Dive into Use Cases, Differences, and Architecture Designs



With the general availability of Microsoft Fabric this past Ignite, there are a lot of questions centered around the functionality of each component but more importantly, what architecture designs and solutions are best for analytics in Fabric. Specifically, how your data estate for analytics data warehousing/reporting will change or differ from existing designs and how to choose the right path moving forward. This article will be focused on helping you understand the differences between the Data Warehouse, Data Lakehouse, and a KQL Database, Fabric solution designs, warehouse/lakehouse/real-time analytics use cases, and to get the best of the Data Warehouse, Data Lakehouse, and Real-Time Analytics/KQL Database.
Topics covered in this article:
- High level description of Microsoft Fabric to have a baseline understanding of the architecture/relevant components.
- High level description of the Data Warehouse, Data Lakehouse, Real-Time Analytics/KQL Database, and OneLake.
- Difference between the Data Warehouse, Data Lakehouse, and Real-Time Analytics/KQL Database.
- Use Cases for Data Warehouse, Data Lakehouse, Real-Time Analytics/KQL Database, or used together.
- Architecture designs for using the Data Warehouse, Data Lakehouse, and Real-Time Analytics/KQL Database.
First, we will cover what Microsoft Fabric is from a high level to have a baseline understanding of the architecture/relevant components for this article as well as the relevant components for discussing the Data Lakehouse, Data Warehouse, and KQL Database in further detail.
What is Microsoft Fabric?
Microsoft Fabric is an all-in-one analytics solution for enterprises that covers everything from data movement to data science, Real-Time Analytics, and business intelligence. It offers a comprehensive suite of services, including data lake, data engineering, and data integration, all in one place.

Microsoft Fabric is built on a SaaS foundation as it brings together new and existing components from Power BI, Azure Synapse, and Azure Data Factory into a single integrated environment. You can interact/build on these components through the experiences such as Data Engineering, Data Factory, Data Warehouse, Data Science, Real-Time Analytics, and Power BI. The advantages of having these components/experiences on one shared platform are:
- An extensive range of deeply integrated analytics in the industry.
- Shared experiences across experiences that are familiar and easy to learn.
- Developers can easily access and reuse all assets.
- A unified data lake that allows you to retain the data where it is while using your preferred analytics tools.
- Centralized administration and governance across all experiences.
Although the components of Fabric use ‘Synapse’ as a prefix for Data Engineering, Data Warehousing, Data Science, and Real-Time Analytics -> this is NOT the same as Azure Synapse Analytics. This can lead to confusion because of naming. The technology is built on top of the existing technology of Synapse but there are a lot of significant changes/improvements to the architecture/functionality that makes it a revolutionized version. Those experienced with Azure Synapse Analytics (Dedicated Pools, Serverless Pools, Spark Pools) will find the concepts of the Microsoft Fabric components familiar, but that the technology/functionality is significantly improved and optimized.
What is OneLake, Data Lakehouse, Data Warehouse, and Real-Time Analytics/KQL Database?
OneLake
OneLake is the data lake that is the foundation on which all Fabric services are built. OneLake is built on top of ADLS (Azure Data Lake Storage) Gen2 and services as the tenant-wide store for data and can support any type of file, structured or unstructured. Every Fabric tenant automatically provisions OneLake, with no extra resources to set up or manage. All Fabric data items like data warehouses and lakehouses store their data automatically in OneLake in Delta Parquet format.
It is a single unified storage system for all developers (professional and citizen) where all compliance, security, and policies are enforced centrally and uniformly. OneLake eliminates the data silos across organizations and eliminating the need to physically copy or move data for different teams/engines to use whether the data is in OneLake or if it is stored in a shortcut compatible location. You can think of OneLake as the OneDrive for you for your organization’s data.
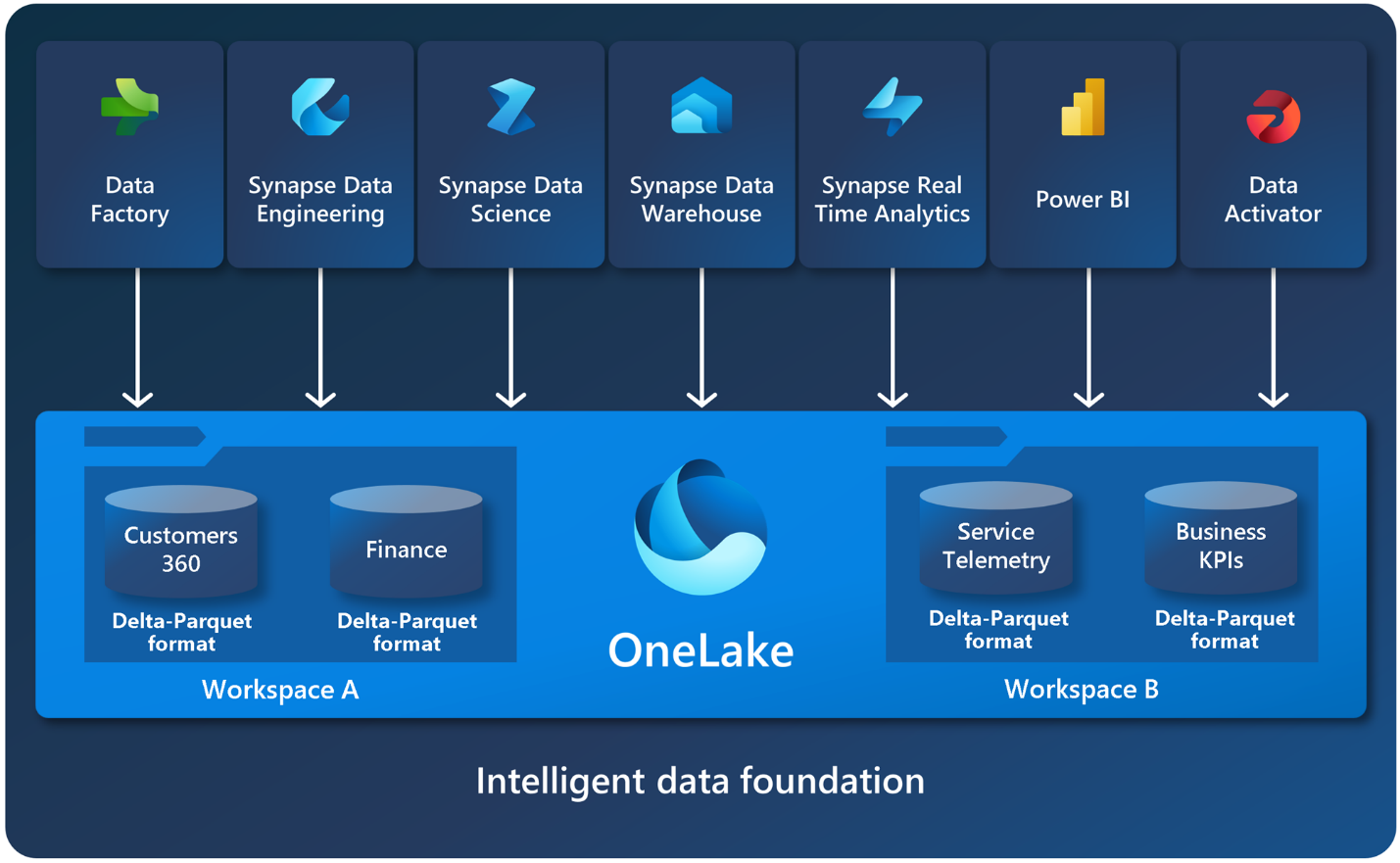
Data Lakehouse
Microsoft Fabric Lakehouse is a data architecture platform for storing, managing, and analyzing structured and unstructured data in a single location, in open format. The default file format is delta parquet. You can store data in 2 physical locations that are provisioned automatically, files (unmanaged) or tables (managed delta tables).
- Tables
- A managed area for hosting tables of all formats in Spark (CSV, Parquet, or Delta). All tables, whether automatically or explicitly created, are recognized as tables in the Lakehouse. Also, any Delta tables, which are Parquet data files with a file-based transaction log, are recognized as tables as well.
- Files
- An unmanaged area for storing data in any file format. Any Delta files stored in this area aren’t automatically recognized as tables. If you want to create a table over a Delta Lake folder in the unmanaged area, you’ll need to explicitly create a shortcut or an external table with a location that points to the unmanaged folder that contains the Delta Lake files in Spark.
The Lakehouse allows you to perform transformations via Spark computes or use SQL endpoints for analysis/exploration of your data. The Data Lakehouse’s default file format is delta parquet which is optimal for analytic workload performance.
Data Lakehouses are not a new concept or proprietary to Microsoft Fabric, as they are very common in analytic workload architectures using the recommended medallion architecture (more on this later). This same concept of a Data Lakehouse is present in Microsoft Fabric with some new functionality and seamless integration with the components inside of Microsoft Fabric and a few other services outside of Microsoft Fabric. Including the ability to provide one copy of your data and share amongst other teams with zero data duplication.
Data Warehouse
Microsoft Fabric Data Warehouse is a lake centric data warehouse built on an enterprise grade distributed processing engine. One of the major advantages of Fabric Data Warehouse compared to other data warehousing solutions is that there is no need to copy the data from a Data Warehouse for other compute engines or teams to consume since the warehouse uses OneLake as its storage. One single copy of the data stored in Microsoft OneLake in a delta parquet format. Because of this, you can have cross-database querying to leverage different sources (OneLake or other sources through shortcuts) of data seamlessly and with zero data duplication.
At its core, the Data Warehouse is a SQL MPP Engine (massively parallel processing engine) with Delta Tables and TDS endpoints, which will provide you with full T-SQL DDL and DML support (check availability of specific functions/features). The compute is a serverless infrastructure to allow for infinite scaling with dynamic resource allocation, instant scaling up or down with no physical provisioning involved, and physical compute resources are assigned within milliseconds to jobs.
Real-Time Analytics/KQL Database
Real-Time Analytics is a fully managed big data analytics platform optimized for streaming, and time-series data. It utilizes a query language and engine with exceptional performance for searching structured, semi-structured, and unstructured data. Real-Time Analytics is fully integrated with the entire suite of Fabric products, for both data loading, data transformation, and advanced visualization scenarios. Just like the rest of the Microsoft Fabric components, Real-Time Analytics is a SaaS experience.
With Real-Time Analytics in Microsoft Fabric, you enable your organization to focus and scale up their analytics solution while democratizing data for the needs of both the citizen data scientist all the way to the advanced data engineer. Real-time analytics have become essential in many scenarios in the enterprise world, such as cybersecurity, asset tracking and management, predictive maintenance, supply chain optimization, customer experience, energy management, inventory management, quality control, environmental monitoring, fleet management, and health and safety. This is achieved through reducing the complexity of data integration. You are able to gain quick access to data insights within a few seconds of provisioning, automatic data streaming, indexing, and partitioning for any data source or format, and on-demand query generation and visualizations. Real-Time Analytics lets you focus on your analytics solutions by scaling up seamlessly with the service as your data and query needs grow.
Read more here What makes Real-Time Analytics unique? To discover more about the advantages of Real-Time Analytics.
Real-Time Analytics uses a KQL database as a data store. We will cover the architecture/components of a Real-Time Analytics solution later in this article, but for now I will give a brief overview of the KQL database. KQL stands for Kusto Query Language, and it is a query language used to interact with data located in a KQL database. KQL database can be used as a general term to apply to both Fabric Real-Time Analytics and Azure Data Explorer since it is referring to a database/store that is interacted with using KQL.
At its core, Real-Time Analytics shares the same core engine with identical core capabilities as Azure Data Explorer, just with different management behavior. (Azure Data Explorer being a PaaS offering and Real-Time Analytics a SaaS offering). So, if you are familiar with Azure Data Explorer then that knowledge is translatable to Fabric Real-Time Analytics, with differences in management.
Azure Data Explorer provides unparalleled performance for ingesting and querying telemetry, logs, events, traces, and time series data. It features optimized storage formats, indexes, and uses advanced data statistics for efficient query planning and just-in-time compiled query execution. Azure Data Explorer offers data caching, text indexing, row store, column compression, distributed data query, separation of storage and compute.
See this documentation to view the differences in functionality/management between the Real-Time Analytics and Azure Data Explorer: Differences between Real-Time Analytics and Azure Data Explorer – Microsoft Fabric | Microsoft Learn
What is the difference between the Data Lakehouse, Data Warehouse, and Real-Time Analytics/KQL Database?
Now that we have a basic high-level understanding of what Microsoft Fabric is, and specifically OneLake, Data Lakehouse, Data Warehouse, and and Real-Time Analytics/KQL Database. It is time to break down the differences between the Data Lakehouse, Data Warehouse, and and Real-Time Analytics/KQL Database so we can better understand the use cases for each and help with designing our solutions.
First, we will focus on the comparison between the Data Lakehouse and Data Warehouse before comparing the and Real-Time Analytics/KQL Database.
Both the Data Lakehouse and Data Warehouse are open data format – delta parquet, lake centric approaches and have some cross functionality, but there are differences that I have broken down into categories.
- How to access/work with the data
- Endpoint being used (more detail below)
- Types of data stored/used
- Developer Skillset
Endpoints for Data Lakehouse and Data Warehouse
There are 3 different endpoints between each the Lakehouse and Data Warehouse.
- Lakehouse Endpoint for Spark Runtimes/Libraries
- SQL Analytics Endpoint of the Lakehouse
- Data Warehouse Endpoint
Lakehouse Endpoint for Spark Runtimes/Libraries
To interact with Lakehouse files/tables for analysis, transformations, or processing using Spark, you will connect to the endpoint for your Lakehouse that is separate from the SQL Analytics Endpoint. Just like standard methods outside of Fabric for interacting with files/delta tables, you will connect using either the URL, ABFS path, or mounting the Lakehouse directly in your explorer. Using Spark allows you to perform write operations with your choice of Scala, PySpark, Spark SQL, or R. However, if you wish to use T-SQL, you will need to use the SQL Analytics Endpoint where you can only perform read-only operations.
SQL Analytics Endpoint of the Lakehouse
This endpoint provides a SQL-based experience for the Lakehouse delta tables. The SQL Analytics Endpoint offers the ability to interact, query, and serve data within the Lakehouse using SQL. This experience is read-only and applies only to delta tables. This would be the ‘Tables’ section of the Lakehouse, and the ‘Files’ section are not readable/discoverable through the SQL endpoint. The SQL Analytics Endpoint allows you to analyze the delta tables using T-SQL, save functions, generate views, and apply SQL object level security. It enables data engineers to build a relational layer on top of physical data in the Lakehouse and expose it to analysis and reporting tools using the SQL connection string.
A SQL Analytics Endpoint is automatically created when you create a Lakehouse, which points to the delta table storage. Each Lakehouse has only one SQL Endpoint, and each workspace can have more than one Lakehouse. This means that the number of SQL Endpoints in a workspace matches the number of Lakehouses.
It is important to note that the creation/modification of delta tables (and the data within the delta tables) must be completed using Apache Spark, Delta Tables that are created through Spark within the Lakehouse are automatically discoverable through the endpoint. And if there are external delta tables that are created with Spark code then they will not be visible to the SQL analytics endpoint until you make a shortcut to the external delta table for it to be visible.
You can set object-level security for accessing data using SQL analytics endpoint. These security rules will only apply for accessing data via SQL analytics endpoint. This means that if you want to make sure your data is not accessible in other ways (through different endpoints or directly) then you must set workspace roles and permissions.
You can connect to this endpoint outside of Fabric as well with tools such as SSMS or Azure Data Studio by supplying your authentication and endpoint connection string just like any other SQL server connection.
Behind the scenes, the SQL analytics endpoint is using the same engine as the Warehouse endpoint to serve high performance, low latency SQL queries. Which means that it is also a TDS endpoint, just with restrictions on the DML/DDL functionality and T-SQL surface limitations when compared with the Data Warehouse endpoint.
It is important to note that MSFT documentation will describe the SQL Analytics Endpoint for the Lakehouse as a Data Warehouse. Although this can be true depending on your context, I will not refer to it as a data warehouse to avoid confusion when discussing the Synapse Data Warehouse. I will explicitly refer to it by the SQL Analytics Endpoint or SQL querying on the Lakehouse.
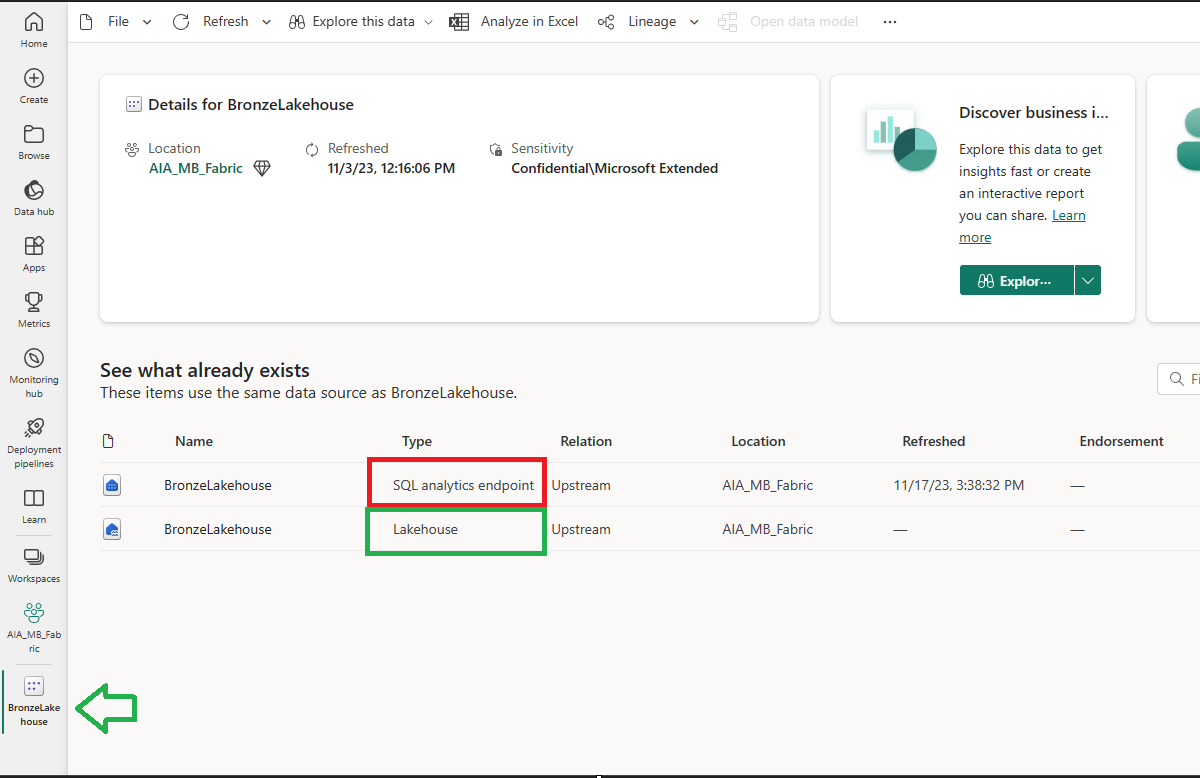
Within my Fabric workspace, I have Lakehouse called ‘BronzeLakehouse’. Within that Lakehouse, I have 2 items (different item types) associated with my Lakehouse. The SQL Analytics Endpoint (red) and the Lakehouse endpoint (green)
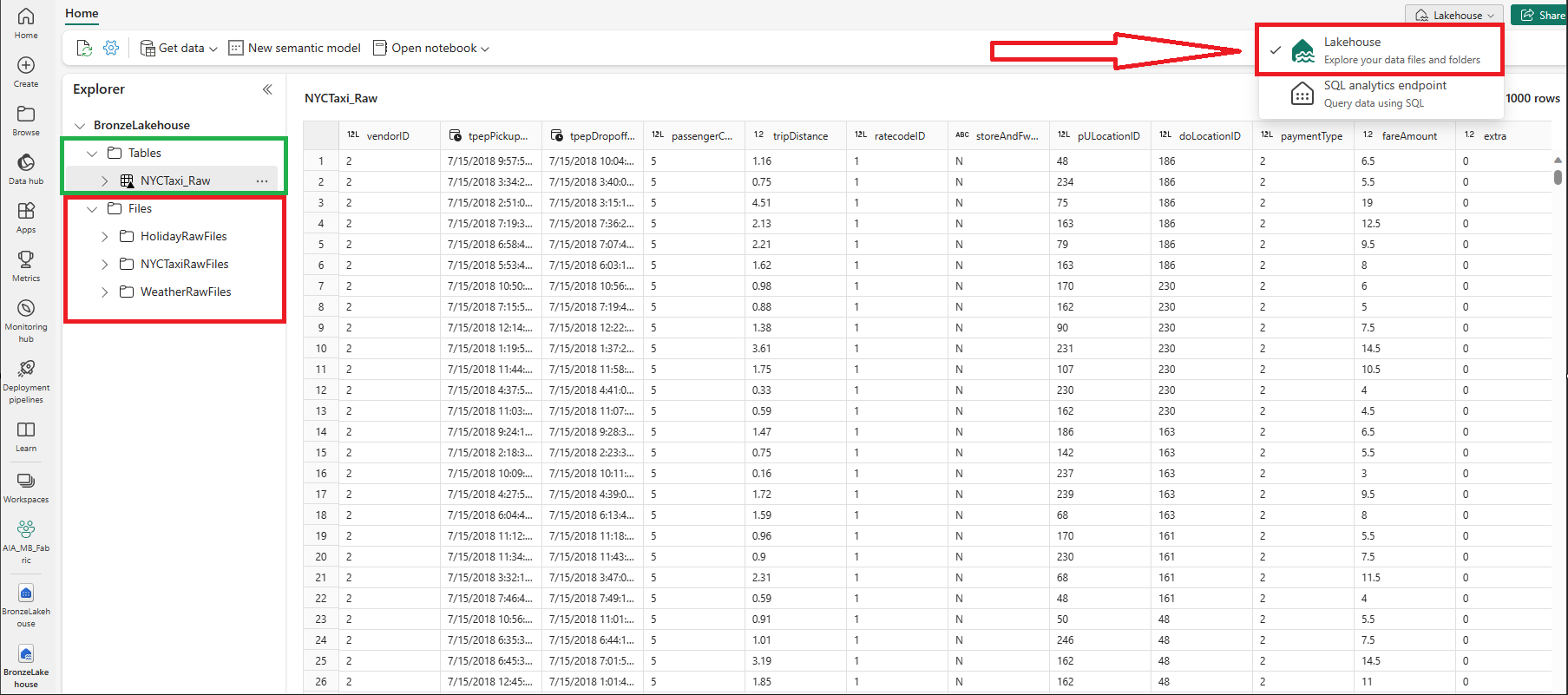
What can I see using the ‘Lakehouse’ endpoint? Files (red) and Delta Tables (green). You can check which endpoint you are currently viewing in the top right corner via a drop-down selection (shown expanded)
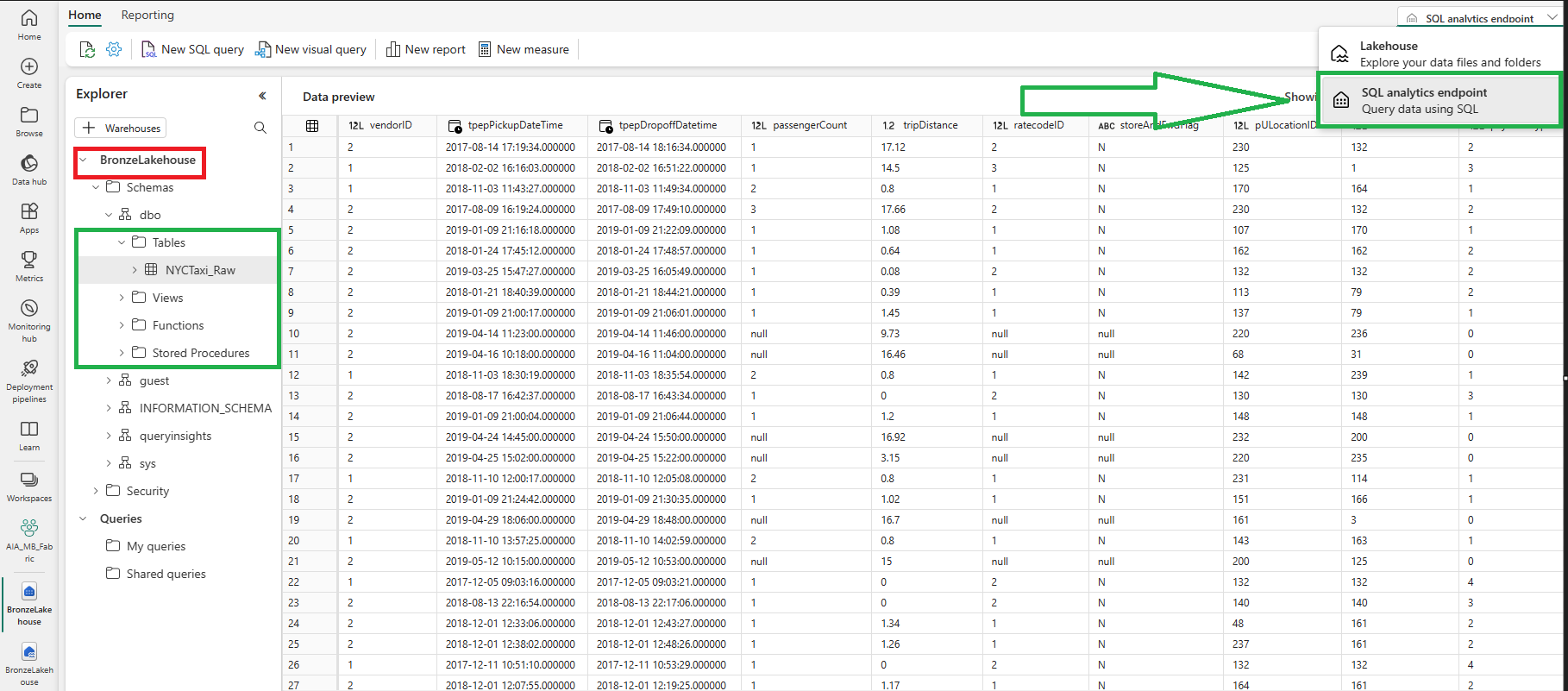
What can I see using the SQL Analytics Endpoint of the Lakehouse? Delta Tables only.
Data Warehouse Endpoint
The Synapse Data Warehouse or Warehouse Endpoint functions in a ‘traditional’ SQL data warehouse fashion. This means that this endpoint supports the full T-SQL capabilities like your enterprise data warehouse. Unlike the SQL Analytics Endpoint, the Data Warehouse Endpoint offers you:
- Read and write support to Delta Tables
- You can read data using spark or T-SQL
- You can write data with only T-SQL
- Full DML and DDL T-SQL support
- Including data ingestion, modeling, and development through TSQL or the UI
- You are fully in control of creating tables, loading, and transforming
- Can use COPY INTO, pipelines, dataflows OR Cross Database ingestion using CREATE TABLE AS SELECT (CTAS), INSERT..SELECT, or SELECT..INTO
- Full ACID compliance and transaction support
- Lakehouse offers ACID compliance support for only Delta Tables. So there can be files/data that would be in a Lakehouse that wouldn’t support ACID compared.
- Multi-table transaction support
Pairing the full read/write capabilities and the cross-database ingestion capabilities, you are able to ingest from multiple Data Warehouses or Lakehouses seamlessly. When ingesting data into the Data Warehouse, it will create a Delta Table that is stored in OneLake.
Here is a diagram that can help explain the difference between the SQL Analytics Endpoint and the Data Warehouse Endpoint.
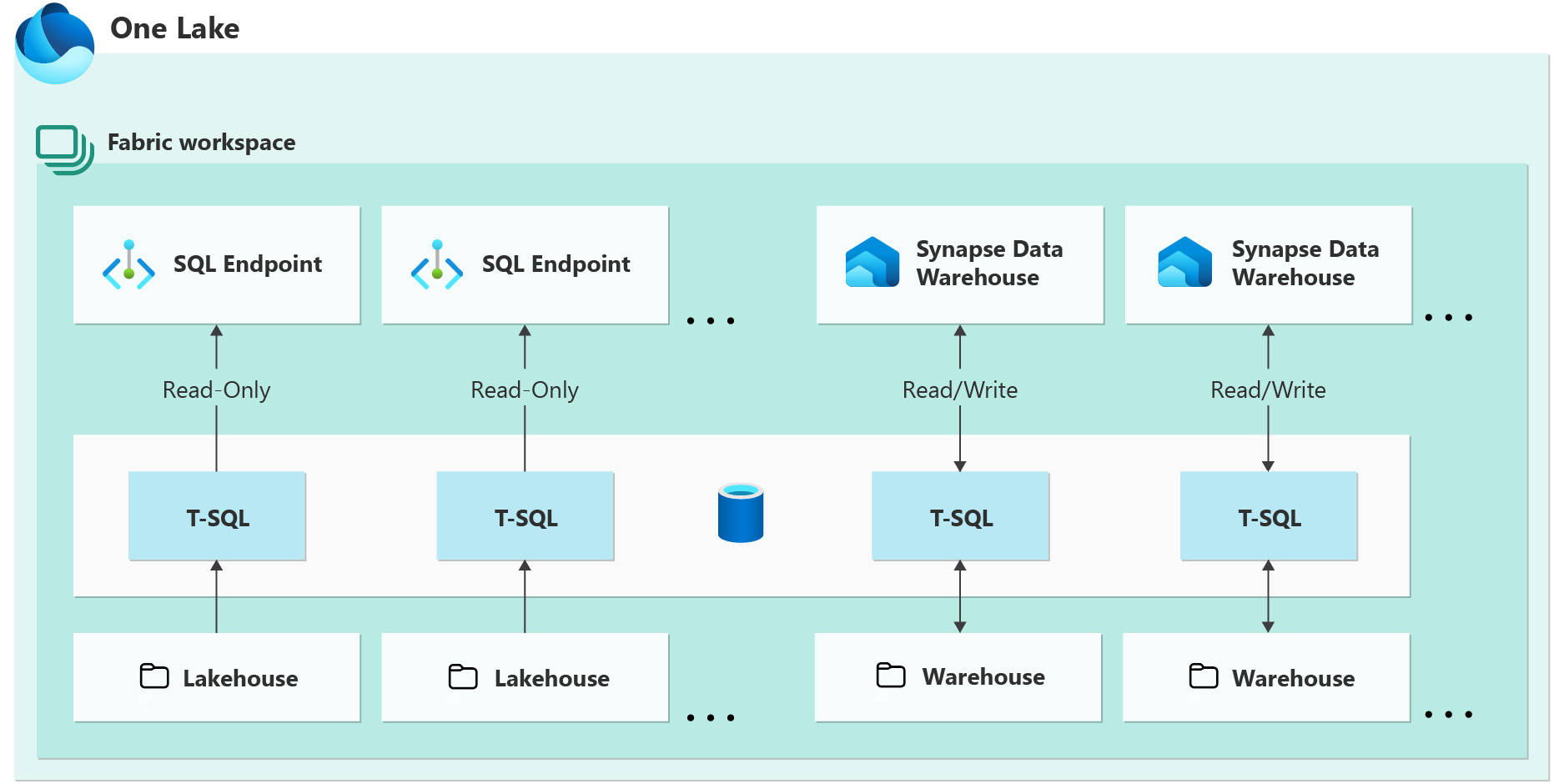
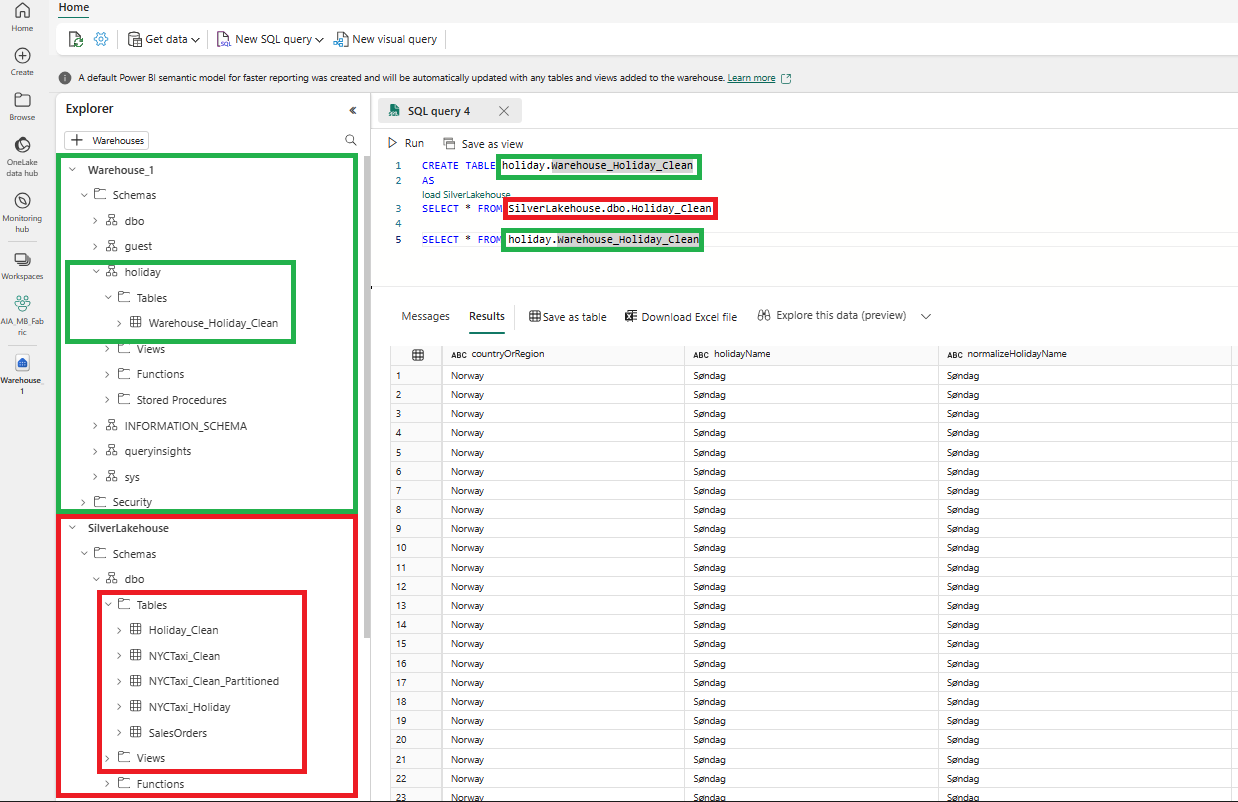
Example of a cross database query to load data into the Data Warehouse from the Lakehouse.
Warehouse table ‘holiday.Warehouse_Holiday_Clean’ is created and loaded with a CTAS statement with the ‘SilverLakehouse.dbo.Holiday_Clean’ delta table as the source.
KQL Database Endpoint
The KQL Database is not a new concept or as complex as the endpoints for the Lakehouse or Data Warehouse. We will discuss the use cases and other factors that differentiate Real-Time Analytics/KQL database from the other offerings, but this section is for the endpoint differences.
There are no limitations on read/write capabilities depending on your language or endpoint as there are not different endpoints for a KQL database. You will be able to read/write using KQL, Spark, connector ecosystem (no code), or T-SQL. Depending on exactly what you are trying to do, there may be a better language or process that you will have to evaluate in a case-by-case basis.
The limitations of read/write capabilities would be applied to the account permissions. KQL databases offer the ability to apply ONLY row level security, which is account specific and not compute engine specific like the Data Warehouse and Lakehouse.
Below are some of the main benefits of using a KQL Database that I want to highlight:
- Manage an unlimited amount of data, from gigabytes to petabytes, with unlimited scale on concurrent queries and concurrent users.
- Built-in autoscale adjusts resources to match workload factors like cache, memory, CPU usage, and ingestion, optimizing performance and minimizing cost.
- Query raw data without transformation, with high performance, incredibly low response time, while using a wide variety of available operators. Queued and Streaming ingestion has a couple of seconds latency.
- Automatic indexing and partitioning of your ingested data to further support high performance at unlimited scale without you managing like in traditional RDMS.
- Any data format can be ingested/analyzed through analytical queries such as free text and JSON structures.
- Support for advanced analytics such as time Series native elements and full geospatial storing and query capabilities
There is also a preview feature called ‘One Logical Copy’. This provides you the ability to create a one logical copy of KQL Database data by enabling data availability in OneLake. Enabling data availability of your KQL database in OneLake means that you can query data with high performance and low latency in your KQL database, and query the same data in Delta Lake format via other Fabric engines such as Direct Lake mode in Power BI, Warehouse, Lakehouse, Notebooks, and more. One logical copy (Preview) – Microsoft Fabric | Microsoft Learn
Types of Data Stored
Another difference between the Data Lakehouse, Data Warehouse, and KQL Database is the type of data that is stored and how it is organized.
Within the Data Lakehouse:
- You can store unstructured, semi-structured, or structured data.
- The data is organized by folders and files, lake databases, and delta tables.
Within the Data Warehouse:
- You can store structured data.
- The data is organized by databases, schemas, and tables (delta tables behind the scenes)
Within the KQL Database:
- You can store unstructured, semi-structured, or structured data.
- The data is organized by databases, schemas, and tables.
Developer Skillset
In many architecture and design sessions, the right service/pattern may not be the best for your team due to skillsets of the team members. For instance, transforming data in Spark may be the best design choice for performance, cost, etc. However, no one on the team has experience or knowledge with Spark or any language besides T-SQL. That will affect your design to consider the availability/uses of your developer’s skillset.
Within the Data Lakehouse:
- The primary skill is Spark(Scala, PySpark, Spark SQL, R)
- This is for write operations and the majority of the workloads
- There can be a secondary skill of T-SQL for read-only operations or analysis thanks to the SQL Analytics Endpoint on the Lakehouse
- The interaction with the data will primarily be through Spark notebooks and Spark job definitions.
Within the Data Warehouse:
- The primary skill is SQL
- This includes T-SQL and related SQL knowledge like data modeling, DDL/DML statements, SQL MPP engine understanding, SQL DBA knowledge etc.
- The interaction with the data will be through SQL scripts.
- Stored procedures, views, ad hoc queries, etc.
- You can read from the Data Warehouse with Spark but it would not be used for consumption/serving.
Within the KQL Database:
- The Primary skills are KQL, SQL, or No Code.
- You will be able to read data with KQL, T-SQL, Spark, and Power BI
- You will be able to write data with KQL, Spark, and the connector ecosystem.
- The interaction with data will be through a KQL Queryset or KQL Database directly.
Here is a chart that provides a comparison between the Data Warehouse, Lakehouse, and KQL Database. You can view the full documentation here: Fabric decision guide – choose a data store – Microsoft Fabric | Microsoft Learn
| Data warehouse | Lakehouse | KQL Database | |
| Data volume | Unlimited | Unlimited | Unlimited |
| Type of data | Structured | Unstructured,semi-structured,structured | Unstructured, semi-structured, structured |
| Primary developer persona | Data warehouse developer, SQL engineer | Data engineer, data scientist | Citizen Data scientist, Data engineer, Data scientist, SQL engineer |
| Primary developer skill set | SQL | Spark(Scala, PySpark, Spark SQL, R) | No code, KQL, SQL |
| Data organized by | Databases, schemas, and tables | Folders and files, databases, and tables | Databases, schemas, and tables |
| Read operations | Spark,T-SQL | Spark,T-SQL | KQL, T-SQL, Spark, Power BI |
| Write operations | T-SQL | Spark(Scala, PySpark, Spark SQL, R) | KQL, Spark, connector ecosystem |
| Multi-table transactions | Yes | No | Yes, for multi-table ingestion. See update policy. |
| Primary development interface | SQL scripts | Spark notebooks,Spark job definitions | KQL Queryset, KQL Database |
| Security | Object level (table, view, function, stored procedure, etc.), column level, row level, DDL/DML, dynamic data masking | Row level, table level (when using T-SQL), none for Spark | Row-level Security |
| Access data via shortcuts | Yes (indirectly through the lakehouse) | Yes | Yes |
| Can be a source for shortcuts | Yes (tables) | Yes (files and tables) | Yes |
| Query across items | Yes, query across lakehouse and warehouse tables | Yes, query across lakehouse and warehouse tables;query across lakehouses (including shortcuts using Spark) | Yes, query across KQL Databases, lakehouses, and warehouses with shortcuts |
| Advanced analytics | Time Series native elements, Full geospatial storing and query capabilities | ||
| Advanced formatting support | Full indexing for free text and semi-structured data like JSON | ||
| Ingestion latency | Queued ingestion, Streaming ingestion has a couple of seconds latency |
Use Cases for Data Warehouse, Data Lakehouse, and Real-Time Analytics/KQL Database
Now that there is a deeper understanding of the differences between the Data Warehouse, Data Lakehouse, and Real-Time Analytics/KQL Database, it is time to review some of the use cases to determine which option to use. There are a lot of specific use cases out there and it would be impossible to cover every possible scenario, so I am going to cover some general scenarios.
To determine whether you should use the Lakehouse alone, Data Warehouse alone, KQL Database alone, or mixing them together, will generally depend on these requirements for your solution.
- How the data is going to be consumed/used
- Requirements for your application or ETL/ELT
- Skillset of developers
- Inclusive of data engineers, data scientists, citizen developers, and professional developers
How the data is going to be consumed/used
When designing a solution, it is important to understand how the data you are working with will be consumed. A Lakehouse, Data Warehouse, and KQL Database have a lot of flexibility/overlapping ability for serving data to users. However, the specific needs/nuances can vary from solution to solution so here are some common examples of different consumption methods for the data:
- Users consuming through Power BI reports/dashboards.
- Lakehouse, Data Warehouse, and KQL Database all can serve Power BI.
- Lakehouse and Data Warehouse both can serve Power BI with the same direct lake mode semantic model capability. (Direct lake mode not discussed in detail here.). Or using import or DirectQuery mode through the SQL Analytics Endpoint of the Lakehouse or the Data Warehouse endpoint.
- KQL Database can only serve Power BI with Direct Lake Mode when the preview feature ‘One Logical Copy’ is enabled. More on this later.
- Business users analyzing/exploring with ad-hoc T-SQL
- Lakehouse, Data Warehouse, and KQL Database all offer the ability for SQL read functionality. Other factors will determine what solution is best.
- Allowing users to consume with Spark directly on files, including unstructured, semi-structured, and structured data and all file types (not just delta tables or delta parquet). This can be for business users, data scientists, etc.
- Lakehouse is the correct use case for this, since any file format can be stored, and Spark can be used to interact with these files. The Data Warehouse allows Spark to read only to the tables, which might be enough but generally, you would not use a Data Warehouse for this scenario.
- KQL Database has the ability to interact with tables using Spark functionality for read and write, however it will depend on other factors like use cases, needs of the ETL/ELT or application, size of the data, etc. to determine if KQL should be used over a lakehouse.
- Mix of consumption: PySpark skills from the Data Engineering team who perform the transformation work/data modeling and business users/developers who consume read-only T-SQL queries whether ad hoc directly, cross-database queries to other Lakehouses/Warehouses in Fabric, or in Power BI.
- Lakehouse would be best for this scenario. Because of the business users consuming read only T-SQL, then they can use the SQL Analytics Endpoint on the lakehouse for their consumption. And the data engineering team can continue to work with the data in Spark.
- There would be no need to use the Data Warehouse, unless there were other requirements/needs that would force the use of the Data Warehouse such as using the warehouse endpoint for third party reporting tools or analytic queries or requiring functionality only available in Data Warehouse
- Ex. Multi-table transactions or DML/DDL capability via SQL
- You can technically use a KQL database for your Real-Time Analytics solution in this scenario, as you can serve/consume data via KQL/SQL queries or in Power BI while performing transformations. And can cross query between the data warehouse, lakehouse, and other KQL databases (via Shortcuts with ‘One Logical Copy’ enabled) KQL databases fulfills the requirements of this scenario, however I would start with a lakehouse first then determine based on other requirements of the solution. More on that as we go on.
- Ex. Needing real-time analytics with high performance and low latency (not ‘near real-time’) or time series and geospatial storing/query support.
Each database, Data Warehouse, Lakehouse, KQL, SQL Server, Cosmos DB, etc., are all optimized for different read/write sizes and workloads. So, understanding these optimizations is key to determining which solution is best based on the requirements.
Requirements for your application or ETL/ELT
For different applications and ETL/ELTs, there can be solution needs that require specific functionality of either a Lakehouse, a Data Warehouse, or Real-Time Analytics/KQL Database. Again, the nuances of every solution make it impossible to cover all scenarios, but I will cover 4 common requirements for applications or ETL/ELT workloads.
ACID transaction compliance
ACID stands for:
- Atomicity
- Each statement in a transaction is treated as a single unit. Either the entire transaction is executed or none of it is.
- Ex. a bank transfer deducting money from your account and transferring it to the other account. Without atomicity, you can deduct money from your account without it reaching the other account.
- Each statement in a transaction is treated as a single unit. Either the entire transaction is executed or none of it is.
- Consistency
- Transactional consistency. Requiring the changes made in a transaction are consistent with any constraints. Prevents any of these errors or corruption from entering your data.
- Ex. You try to withdraw more money from an ATM than is in your account. Transaction fails since it prevents an overdraft, violating a constraint.
- Transactional consistency. Requiring the changes made in a transaction are consistent with any constraints. Prevents any of these errors or corruption from entering your data.
- Isolation
- All transactions are run in isolation without interfering with each other. If there are multiple transactions applying changes to the same source, then they will occur one by one.
- Ex. You have $1,000 in a bank account. You send 2 simultaneous withdrawals for $500 each. If these happen at the same time, then your ending balance would be $500. But with isolation, the ending balance would be $0 since each transaction impacted the other.
- All transactions are run in isolation without interfering with each other. If there are multiple transactions applying changes to the same source, then they will occur one by one.
- Durability
- Ensuring that the changes made to the data persist. Whether this is writing to a database, saving a file, etc. Just that the changes are available in case of a crash or system failure.
Why ACID is important?
- Being ACID compliant allows for the best data integrity and reliability possible by never allowing your data to be in an inconsistent state.
What does ACID compliance look like in the Lakehouse and Data Warehouse?
- Lakehouse ACID Compliance
- ACID transaction capabilities are ONLY for Delta formatted tables.
- This means you must utilize the managed Delta Tables to have ACID functionality.
- Delta Tables extend parquet files with a file-based transaction log for ACID transactions.
- You can interact/have ACID support for Delta Tables with the Spark or SQL engine.
- Non-Delta Tables AKA, all other files, will not have ACID support in the Lakehouse.
- Data Warehouse ACID Compliance
- ACID transactions are fully supported in the Data Warehouse for all tables.
- All tables are Delta Tables stored in OneLake as delta parquet files with a file-based transaction log.
- KQL Database ACID Compliance
- ACID transactions are NOT supported in KQL databases.
- A KQL Database is a distributed system supporting eventual consistency and does not support transactions.
- There is an ability to use an ‘update policy’ to apply ingestion updates to multiple tables however this is not ACID as there are limitations to this and they do not function as transactions to support ACID compliance.
- A KQL Database is a distributed system supporting eventual consistency and does not support transactions.
- ACID transactions are NOT supported in KQL databases.
Multi-table Transactions
Multi-table transactions are a way to group changes to multiple tables into a single transaction. This allows you to control the commit or rollback of read and write queries, and modify data that is stored in tables using transactions to group changes together.
Ex: You change details about a purchase order that affects three tables (dbo.ItemStock, dbo.PurchaseOrderHistory, dbo.OrderShippingInfo). You can group the transaction of cancelling an order so that the changes will apply to all 3 tables or none at all. So, when a user queries any of the tables, they will see the consistent change across all tables, and not contradicting/incorrect data.
Multi-table transactions are ONLY supported in the Data Warehouse.
The Lakehouse currently does not support this functionality.
KQL Databases do not support transactions, it’s a distributed system supporting eventual consistency. A KQL Database can achieve an update behavior similar to multi-table transaction via the ‘update policy’ but this is not ACID compliant nor guaranteed order of execution/durability.
Dynamic Data Masking
Dynamic data masking limits sensitive data exposure by masking it to nonprivileged users. It helps prevent unauthorized viewing of sensitive data by enabling administrators to specify how much sensitive data to reveal, with minimal effect on the application layer.
- Some sensitive fields that are commonly masked for business users are SSNs, emails, account numbers, PHI, etc.
Lakehouse Data Masking:
- Supported only through the SQL analytics endpoint of the Lakehouse. Files or engines other than SQL (Ex. Spark) will not be able to use Dynamic Data Masking.
- Can also apply object and row level security (along with DDM) but only through the SQL Analytics Endpoint.
- Spark engines will not be able to use the object and row level security.
- This may change in the future through OneLake Security. Can view more about the public roadmap here. What’s new and planned for OneLake in Microsoft Fabric – Microsoft Fabric | Microsoft Learn
Data Warehouse Data Masking:
- Fully supported.
- In addition to dynamic data masking, the data warehouse supports SQL granular permissions, column and row level security, and audit logs.
KQL Database Data Masking:
- None.
- You can apply row level security or restricted view access policy on a table or try to create views or functions that only expose select columns however there is no support for masking or encrypting sensitive data.
Real-Time Analytics
The general explanation of what Real-Time Analytics is being able to process, view, analyze, and measure data as soon as it has been collected. This means that data must be available for consumption with extremely low latency, such as within a few seconds. The solution must be able to handle large amounts of data while providing that few second latency from collection. The size you want to think of is going to be in petabytes and higher with the data format widely varying. Some of the general use cases for Real-Time Analytics involve security audit logs, inventory data, supply chain information from assets on a production floor to the delivery trucks and streaming smart device information in any industry.
Data Warehouse:
- The Data Warehouse is not a great use solution for Real-Time Analytics.
- The data size, format, and latency requirements do not make the Data Warehouse an option for Real-Time Analytic solutions.
- However, you can ingest the data from your Real-Time Analytics solution into your Data Warehouse for further analysis or combine with your existing data for further value.
Lakehouse:
- The Lakehouse could be an option for Real-Time Analytics, but it will depend on the requirements of the solution if it is even possible. The Lakehouse could be a choice, but it is not the first one.
- IF you have millions of transactions per second with only 100-500 rows of data per transaction, well the Lakehouse may be able to support the needs of the Real-Time Analytics solution. As this falls into the potential performance/latency expectations of a Lakehouse solution. However, if those millions of transactions per second have hundreds of thousands or millions of rows per transaction, then the Lakehouse will not be able to handle this and is not a possible option.
- It will depend on the concurrency and size of the data to determine whether the Lakehouse would even be able to achieve the low latency and high-performance requirements.
KQL Database:
- KQL Database is the best choice for Real-Time Analytics solutions. Hands down.
- KQL databases are optimized for very large writes and high concurrency. The example of the millions of transactions per second with hundreds of thousands of rows in each transaction will be able to be handled in a performant manner with KQL databases.
- With the automatic indexing and partitioning of the tables/data within the KQL database and the support for all data formats, this is the best solution for handling any Real-Time Analytics solutions.
Each database, Data Warehouse, Lakehouse, KQL, SQL Server, Cosmos DB, etc., are all optimized for different read/write sizes and workloads. So, understanding these optimizations is key to determining which solution is best based on the requirements.
Summary of Requirements for your application or ETL/ELT
These are just 4 examples of common requirements within analytic solutions that will dictate which component to use, Lakehouse, Data Warehouse, or KQL Database.
For ACID compatibility, you will need to review the requirements of the solution/other factors since utilizing the ACID capability in either the Data Warehouse and Lakehouse; you will need to create a Delta Table (all tables in the Lakehouse and Data Warehouse are Delta Tables). This means there is likely a need to either convert a file into a Delta Table or load directly into one for both components. You will not be able to use a KQL Database. So, the choice will depend on the other factors for the use cases such as skillset, other requirements, and consumption.
For multi-table transactions, you will need to use the Data Warehouse over the lakehouse and KQL Database to perform these transactions. Understanding this can save you a lot of headaches and time when designing your solution/functionality for your users.
For dynamic data masking, you can use either the Data Warehouse or the Lakehouse and KQL Database to achieve this functionality. IF using a SQL endpoint for the Lakehouse. If you have need for files to have Dynamic Data Masking or other engines like Spark, then you can certainly try to design your Lakehouse to remove sensitive columns and expose different versions of the data to the business users, however that can quickly become unmanageable depending on the scale. The data warehouse offers the ability to have a one stop shop for business users and protects sensitive information via dynamic data masking without worrying about the use of files or other engines.
For Real-Time Analytics, you will want to use KQL Database. You may be able to use the Lakehouse depending on the exact requirements, but KQL Databases are optimized/designed for this exact scenario. As always, you can certainly try to design a solution in the Lakehouse, but the KQL database is just more performant for this scenario and has many optimizations out of the box. Data Warehouse is not a good choice for Real-Time Analytics solutions.
Skillset of Developers
The last major category of the use case decisions is the skillset of your developers. This includes citizen developers, professional developers, data engineers, data scientists, etc. An important piece of information when I advise customers on architecture decisions is understanding the skillset of the individuals working with the data. The most optimal service/design for performance and cost may not be the best solution for the team since no one would know how to develop it.
- A silly example of this concept is if you are trying to have your team individually drive a car from point A to point B. You decide that the fastest way to get there is to provide your team with only manual transmission vehicles (stick shift) because they are faster than automatic transmission vehicles. If you know how to drive stick shift, then you won’t have a problem getting there quickly. However, if your entire team doesn’t know how to drive stick shift, then they will take even longer/run into issues using the manual transmission. Supplying an automatic transmission vehicle instead of a manual transmission may not be the best option, objectively, but it may be the best option for your team.
High-level breakdown of the skillsets used and the types of developers for the Lakehouse, Data Warehouse, and KQL Database.
- Lakehouse
- Developers/Users with Spark knowledge and preference. Working directly with files and or Delta Tables for the ETL/ELT or other workloads. This includes working with Spark notebooks and Spark job definitions.
- Usually data engineers, data scientists, and professional developers
- Developers/Users with only T-SQL knowledge to only read the data curated for them (in Delta Tables via the SQL Analytics Endpoint) for consumption or analysis.
- Usually, citizen developers and professional developers
- Developers/Users with Spark knowledge and preference. Working directly with files and or Delta Tables for the ETL/ELT or other workloads. This includes working with Spark notebooks and Spark job definitions.
- Data Warehouse
- Developers/Users with T-SQL knowledge and preference while building an ETL/ELT. Data Warehousing experts working with stored procedures, functions, and DBA tasks.
- Usually data warehouse engineers, and SQL developers
- Developers/Users with only T-SQL knowledge to only read the data curated for them for consumption or analysis.
- Usually, citizen developers and professional developers
- Developers/Users with T-SQL knowledge and preference while building an ETL/ELT. Data Warehousing experts working with stored procedures, functions, and DBA tasks.
- KQL Database
- Developers/Users with KQL knowledge and preference. You will be able to interact with the data (read/write) with Spark or T-SQL statements however KQL is the best choice for interacting with the data at this time.
- Developers/Users can consume via Power BI connectors or different views, queries, or functions as a source.
- Developers/Users with KQL knowledge and preference. You will be able to interact with the data (read/write) with Spark or T-SQL statements however KQL is the best choice for interacting with the data at this time.
Use Case Conclusion
After reviewing some general use cases combined with the different requirements that you may have, it should be clearer when to use a Lakehouse vs a Data Warehouse vs a KQL Database. Often these decisions are complicated and require a lot of factors to be considered. By starting with analyzing how the data is going to be consumed/used, the requirements for your application or ETL/ELT, and the skillset of developers/users; your design/architecture decisions can be made quicker. And if not, then at the very least, you will find out what other questions to ask.
Solution Architectures/Designs For Data Lakehouse, Data Warehouse, and Real-Time Analytics/KQL Database
Understanding the functionality, feature support, use cases, and differences between the Data Lakehouse, Data Warehouse, and a KQL Database will assist you in building an architecture for different types of solutions. We will combine everything we have learned so far and apply it to architectures for different workloads/scenarios.
These examples are not intended to be reference architectures or recommendations of specific best practices across all scenarios, as we covered just some of the complexities that need to be considered.
The goal is to demonstrate architectures using the Lakehouse exclusively, Data Warehouse exclusively, Real-Time Analytics/KQL Database exclusively, the Lakehouse and Data Warehouse together, and Real-Time Analytics/KQL Database and a Lakehouse or Data Warehouse together to provide a better understanding of different design patterns based on your criteria.
The solution architecture/design will be broken into these categories:
- Medallion architecture concept review
- Lakehouse example architecture
- Data Warehouse example architecture
- Lakehouse and Data Warehouse combined architecture
- Real-Time Analytics/KQL Database architecture
Medallion Architecture Concept Review
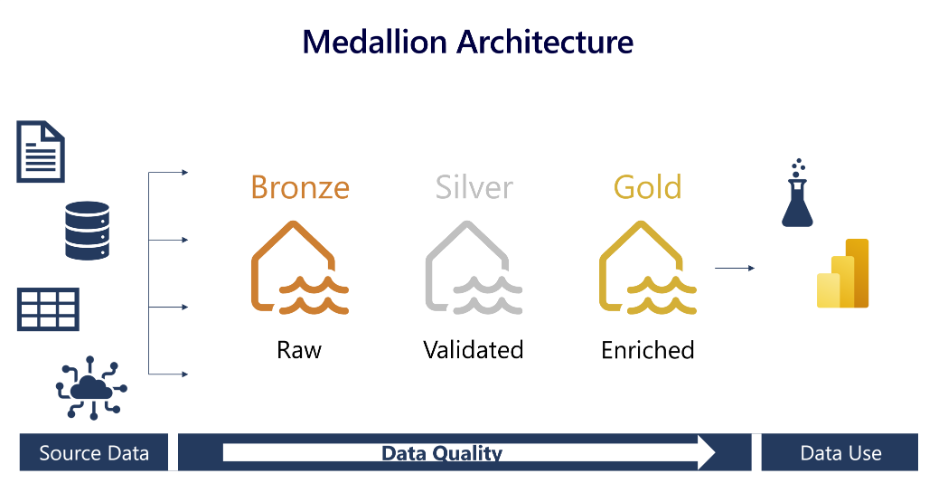
A medallion architecture is not unique to Fabric and has been best practice/very common for lakehouse/data warehousing architectures in the cloud. And it continues to be best practice in Fabric. So it is important that we review the basics of a medallion architecture before diving into specific architectures using it. The medallion architecture is the recommended approach in Fabric.
The medallion architecture describes a series of data layers that denote the quality of data stored in the lakehouse. A medallion architecture comprises of three distinct layers or zones: bronze (raw), silver (validated), and gold (enriched). Each layer indicates the quality of data stored in the lakehouse, with higher levels representing higher quality.
The names of the zones, like ‘validated’ for the silver zone, can vary across sources and designs but concepts are the same.
Bronze
Raw zone. First layer that stores the source data in its original format.
Typically, there is little to no user access at this layer.
Silver
Enriched zone. Raw data that has been cleansed and standardized. The data is now structured with rows and columns, and can be integrated with other sources across the enterprise.
Transformations at the silver level should be focused on data quality and consistency, not on data modeling.
Gold
Curated zone. Final layer sourced from the silver layer. This data is refined, “business ready”, and meets analytical/business requirements.
This can be the Lakehouse or a Data Warehouse depending on needs. More on this design below.
You can have multiple gold layers for different users or domains with specific optimizations/designs. For example, you might have separate gold layers for your finance and sales which is utilizing a STAR schema and optimized for analytics/reporting. And you might also have a gold layer for your data scientists that is optimized for machine learning.
Lakehouse Example Architecture
Here is an example of a Lakehouse architecture utilizing a medallion architecture. Below are notes on different sections of the diagram.
General decision points for using this architecture pattern:
- Developer team skill set is primarily Spark.
- There is no need for additional capabilities of the Data Warehouse like multi-table transactions and dynamic data masking.
- Consumption does not need to use the Data Warehouse endpoint for functionality that some third-party reporting tools require.
- T-SQL DDL/DML capability is not required by users/developers.
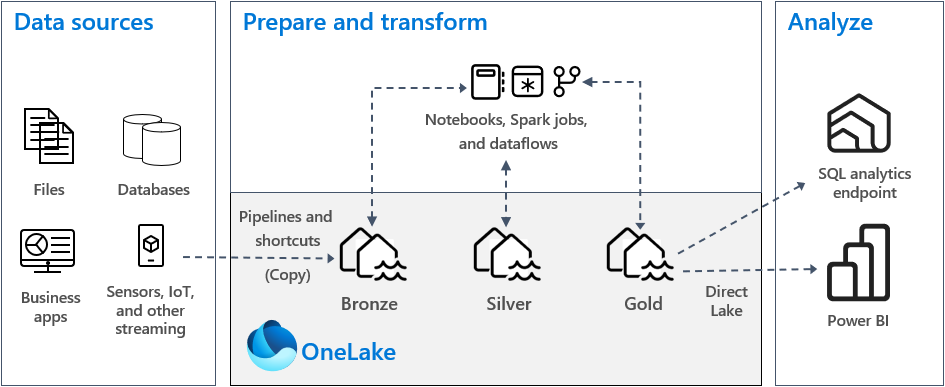
Data Sources:
- Can be any source from files to streaming data and everything in between.
- This data can be sourced from an on-premises location, Azure location, other cloud providers locations, shortcuts, or inside of Fabric itself.
Prepare and Transform:
Ingestion methods:
- We did not cover ingestion methods in detail, but you can choose a variety of no code, low code, or code options.
- The goal is to land the data in the Bronze Lakehouse (raw layer).
- Fabric pipelines
- 200+ native connectors are part of the Microsoft Fabric Pipelines.
- Dataflows
- Shortcuts
- Data source is either: OneLake, Azure Data Lake Store Gen2 (ADLS Gen2), Amazon S3, or Dataverse.
- Spark notebooks/jobs
- Includes streaming data and file/database connection.
- Fabric pipelines
Transformation/data promotion methods for all zones:
- Will depend on the skillset for no code, low code, or code options.
- Spark
- Can be notebooks or Spark Job Definition
- Preferred method for complex scenarios and high code option. Performance will be best here for complex transformation scenarios.
- Dataflows
- Low code option to perform simple transformations and best for small datasets.
- Orchestration by Microsoft Fabric Pipelines
- Spark
Bronze Lakehouse:
- Whenever possible, keep the data in its original format. If that is not possible then use Parquet or Delta Parquet as the conversion target.
- The reason is performance.
- Loading the data into the Lakehouse will allow you to leverage better performance from OneLake/Azure location and the optimizations and scalable serverless compute available in Fabric to do any transformations or conversions necessary. Versus doing that conversion midflight where you may not be able to leverage the optimized scalable compute/low latency.
- If the source data is compatible for a shortcut then create one in the bronze zone instead of copying the data across.
Silver Lakehouse:
- Recommended to use Delta tables if possible.
- There are extra capabilities and performance enhancements built into Fabric specifically for Delta Tables.
- Such as, V-Order write-time optimization to the parquet file format. Which allows extremely fast reads by the different compute engines available in Fabric.
- Ex. SQL engine, Power BI engine, Spark engine
- Such as, V-Order write-time optimization to the parquet file format. Which allows extremely fast reads by the different compute engines available in Fabric.
- This area you will start to enrich your data. The specifics will depend on what is needed to be done. Whether it is combining other data sources together, transforming your existing data, data cleansing, etc. the silver zone is the area to perform these actions.
Gold Lakehouse:
- Same recommendation for using Delta Tables as the Silver Lakehouse.
- This area will be “business ready” Lakehouse. Meaning that you have your data in a STAR schema data model, data is normalized, and business logic has been applied so the data is ready for consumption.
*It is recommended that each Lakehouse be separated into its own Fabric Workspace. This allows better control and governance at each zone level compared to having all the Lakehouses in a single workspace.
Analyze:
Users will consume and analyze the data through 2 methods:
SQL Analytics Endpoint of the Gold Lakehouse
Users/teams can pull data into different reporting tools and even cross database query between Lakehouses and Data Warehouses for different reporting need.
This is also the method for exploration or ad hoc analysis. Whether it is business users or SQL analysts/developers, the SQL Analytics endpoint offers the ability to have a full, read-only, SQL experience all from the Gold Lakehouse.
Through the SQL Analytics Endpoint, privileged users can apply object level and row level security to protect sensitive data. You can create views and functions to customize and control your end user’s experience an access just like a traditional SQL environment that many users are used to.
Power BI
Users/teams will consume data through Power BI via reports, datasets, dashboards, apps, etc. That are sourced from the Gold Lakehouse.
Direct lake mode is a new semantic model capability for parquet formatted files to load directly from the data lake without having to query a Lakehouse endpoint OR import/duplicate data within the Power BI model.
- Learn about Direct Lake in Power BI and Microsoft Fabric – Power BI | Microsoft Learn
- You can still use Import mode and DirectQuery if needed as well from the Gold Lakehouse.
Data Warehouse Example Architecture
Here is an example of a Data Warehouse architecture. Below are notes on different sections of the diagram.
General decision points for using this architecture pattern:
- Developer team skill set is primarily T-SQL/Data Warehousing skillset.
- Transforming data with stored procedures
- There is a requirement to support functionality like multi-table transactions which is only supported by the Data Warehouse.
- Such as transactional workloads (OLTP vs OLAP).
- Does not mean that transactional workloads can ONLY use Data Warehouse. They can use Lakehouse depending on the requirements of the application or ETL/ELT.
- Such as transactional workloads (OLTP vs OLAP).
- Consumption requires a Data Warehouse endpoint for functionality not available in the Lakehouse SQL endpoint that are required for third-party reporting tools or processes.
- T-SQL DDL/DML capability is required by users/developers.
- Your workload requires users to be able to modify data even after it has been normalized or transformed.
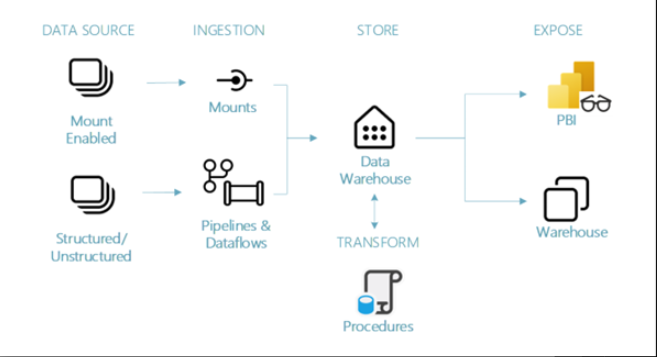
Data Source:
- ‘Mount Enabled’ is referring to shortcuts. It is recommended if you are able to use a shortcut then use it. Shortcuts allow you to use the data without physically copying or moving it.
- Data source is either: OneLake, Azure Data Lake Store Gen2 (ADLS Gen2), Amazon S3, or Dataverse.
- Structured/Unstructured
- Includes data from other Azure Data Services, other cloud platforms, on-premises sources, etc.
Ingestion:
- ‘Mounts’ are referring to mounting an existing Azure Data Factory to leverage existing infrastructure to load data into Fabric and specifically the Data Warehouse.
- Pipelines & Dataflows
- Fabric Pipelines offers the ability to ingest data into your warehouse with 200+ native connectors.
- You can use copy activities in pipelines to land the data or dataflows to land the data with in-flight transformations if needed.
- Those familiar with Azure Data Factory will find similar functionality and concepts within Fabric Pipelines.
Store:
Warehouse Design:
Although not shown in the diagram, it is still recommended to have clear separation of data zones within your Data Warehouse design. Just like a medallion architecture but using the Data Warehouse instead of a Lakehouse. Data Warehouses often have the same concept as a medallion architecture, with some concept of a landing zone, staging zone, and production zone which provide the same benefit as the medallion architecture.
It is recommended to implement this concept into your Fabric Data Warehouse as well. To accomplish this, there are 2 options depending on the amount of administrative oversight tolerable.
- Separate the bronze, silver, and gold layers into separate Data Warehouses within their own workspace.
- You can still cross query to different warehouses to facilitate the data movement/use data, but this offers a natural security and governance border.
- Single warehouse with schema/table enforcement for the different zones.
- This can cause a lot of overhead and sprawl but can work for smaller data warehouses with not a lot of objects/security requirements.
- Each zone would be depicted in a schema and provide the bronze, silver, and gold within the single warehouse through schemas.
- Ex. bronze.Patient, silver.Patient, gold.Patient
- You will want to enforce different object level security to prevent users from discovering/interacting with data they shouldn’t, like sensitive data, raw data, etc.
- SQL granular permissions, object/schema security, row/column level security, and dynamic data masking can all be used
- Can be a lot to manage at scale.
Data Transformations:
- SQL stored procedures are recommended.
- This is through the full DDL/DML capability in the warehouse.
- Your ETL (transforming with SQL stored procedures) can be orchestrated through Fabric pipelines like ADF now.
Expose:
Warehouse:
- Users/teams can pull data into different reporting tools and even cross database query between Lakehouses and Data Warehouses for different reporting needs.
- This is also the method for exploration, ad hoc analysis, or users performing DDL/DML statements.
- Whether it is business users or SQL analysts/developers. Using SQL granular permissions, you can define the level of access/permission each user/security group/user has.
- You can apply object level, row level, and column level security with dynamic data masking to prevent exposing sensitive data.
- You can create views and functions to customize and control your end user’s experience and access just like a traditional SQL environment that many users are used to.
- 3rd party reporting tools or other processes that require functionality only available through the Data Warehouse endpoint.
Power BI:
- Users/teams will consume data through Power BI via reports, datasets, dashboards, apps, etc. That are sourced from the gold warehouse or tables.
- Direct lake mode is a new semantic model capability for parquet formatted files to load directly from the data lake without having to query a warehouse endpoint OR import/duplicate data within the Power BI model.
- Learn about Direct Lake in Power BI and Microsoft Fabric – Power BI | Microsoft Learn
- You can still use Import mode and DirectQuery if needed as well from the gold warehouse or tables.
Data Warehouse & Lakehouse Example Architecture
Here is an example of a Data Warehouse and Lakehouse combined architecture. Below are notes on different sections of the diagram.
General decision points for using this architecture pattern:
- Developer team skill set is primarily Spark.
- Transforming data with Spark notebooks
- There is a requirement to support functionality like end user DDL/DML ability via T-SQL which is only supported by the data warehouse.
- Your workload requires users to be able to modify data even after it has been normalized or transformed.
- Consumption requires functionality from the Data Warehouse endpoint that some third-party reporting tools or processes.
This architecture diagram is the same as the Lakehouse medallion architecture diagram except with 2 differences.
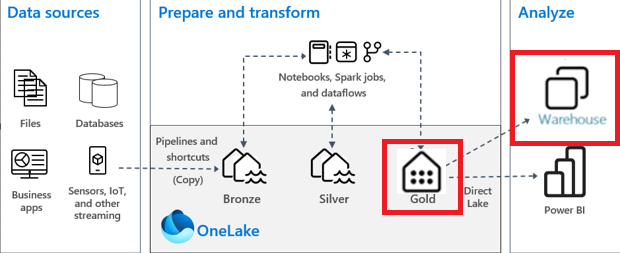
Differences between this architecture and the Lakehouse only architecture:
- Gold Lakehouse is replaced by a Gold Data Warehouse.
- Consumption through the SQL Analytics Endpoint of the Lakehouse is replaced by the Data Warehouse endpoint.
Why would you combine the architectures?
Combining both the Lakehouse and Data Warehouse into a single architecture can provide you with the best of both worlds (depending on your requirements).
With this architecture, you allow the consumption layer (through Power BI or warehouse endpoint) to take full advantage of the Data Warehouse like DDL/DML support for users/developers at the gold layer and Data Warehouse endpoint for other reporting tools/processes – while not having to sacrifice performance or duplicate data just for a different consumption method. All the data transformations within the ETL/ELT are performed with Spark to achieve the best performance and flexibility of your code while leveraging the primary skillset of the developers and still allowing the best end user experience/functionality.
Real-Time Analytics/KQL Database Example Architecture
Here is an example of a Real-Time Analytics/KQL Database architecture. Below are notes on different sections of the diagram.
General decision points for using this architecture pattern:
- Requirement for Real-Time data analysis (latency in seconds)
- Often customers explain a need for “Real-Time” requirements, and after discussion, the requirement is to be “Near-Real-Time”. Meaning that the latency requirements are not in seconds, but in hours, or minutes. The “Near-Real-Time” is sometimes misunderstood to mean Real-Time. This distinction is important as Real-Time Analytics is referring to the latency in seconds. Depending on other requirements, Near-Real-Time solutions may not use KQL Databases.
- KQL Databases offer high performance, low latency, and high freshness even at very large scale.
- There is a requirement to have unlimited scale.
- This unlimited scale applies to query concurrency/size, ingestion streams/size, and storage size.
- Everything is automatically indexed and partitioned within a KQL database.
- This unlimited scale applies to query concurrency/size, ingestion streams/size, and storage size.
- Requirements for real-time data transformation of complicated data structures.
- Requirements to use any data source and/or any data format.
- Requirements to use a timeseries database and/or geospatial functionality built in.
- Consumption can be through Power BI, Notebooks in the Lakehouse, Data Pipelines/Dataflows, or user queries.
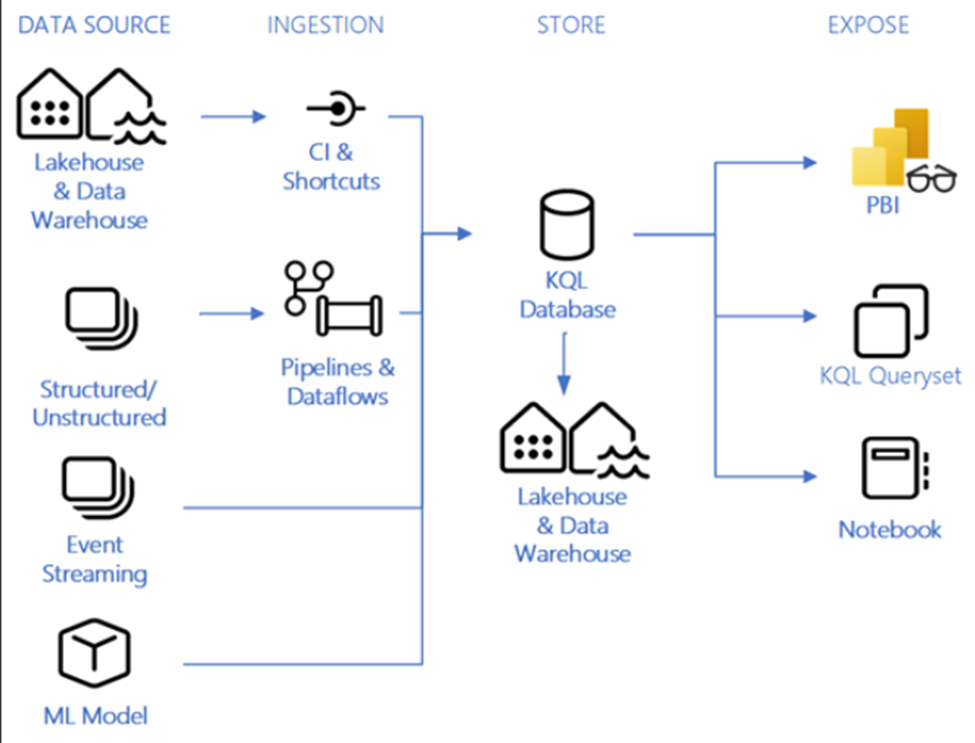
Data Source:
- Any data source and any data format can be used here.
- Lakehouses and Data Warehouses, can have cross database queries and also be a source for the KQL Database.
- Event streaming sources like Event Hubs, IoT Hubs, or other open-source ecosystems (Kafka, Logstash, Open Telemetry, etc.) are possible to use KQL Databases as their streaming targets.
Ingestion:
- Streaming data into Real-Time Analytics through an Event Hubs cloud connections Get data from Azure Event Hubs – Microsoft Fabric | Microsoft Learn
- The event streams feature in Microsoft Fabric gives you a centralized place in the Fabric platform to capture, transform, and route real-time events to various destinations with a no-code experience.
- Everything in Fabric event streams focuses on event data. Capturing, transforming, and routing event data are the essential capabilities of eventstreams. The feature has a scalable infrastructure that the Fabric platform manages on your behalf.
- Shortcuts. It is recommended if you are able to use a shortcut then use it. Shortcuts allow you to use the data without physically copying or moving it.
- Data source is either: OneLake, Azure Data Lake Store Gen2 (ADLS Gen2), Amazon S3, or Dataverse.
- Pipelines & Dataflows
- Fabric Pipelines offers the ability to ingest data into your warehouse with 200+ native connectors.
- You can use copy activities in pipelines to land the data or dataflows to land the data with in-flight transformations if needed.
- Those familiar with Azure Data Factory will find similar functionality and concepts within Fabric Pipelines.
- Data Residing in OneLake
- Data loaded into Real-Time Analytics is reflected in OneLake as one logical copy. One logical copy (Preview) – Microsoft Fabric | Microsoft Learn
- Data from OneLake can be queried from Real-Time Analytics as a shortcut.
- Data from OneLake can be loaded into Real-Time Analytics via pipelines, queries, dataflows, or manually in the Fabric UI.
Store:
KQL Database:
KQL Database is the data store for Real-Time Analytics. All the benefits and use cases are above. A medallion architecture would not be used in the KQL Database, as this is meant for raw telemetry data and modeling/cleansing occurs either midflight or at the consumption layer. It is still recommended to have some sort of organization or naming convention in your KQL objects.
One important concept for designing your Real-Time Analytics solution is archiving. You will want to have an archiving strategy set in place to prevent the data from growing/incurring costs if not needed. Why would you want to archive data? Well, most likely, the data in your Real-Time Analytics solution is valuable for only a short period of time, and for more historical analysis you have different assets. Each solution has different requirements and business needs so the amount of data to be retained can vary but very rarely is there a true requirement to keep all the data in a Real-Time Analytics solution.
- For example, in manufacturing, knowing the current status of production floor machinery is of paramount importance for the dashboard/analysis. However, what the status was 30 days ago at a specific time or even 3 days ago is not relevant or useful for the scope. This is where archiving the data will allow you to either delete the data or move it somewhere else to provide deeper analysis/trending, combine with warehouse data, or any other uses you may have for it. This will help performance and cost.
Within Real-Time Analytics, you can define data retention policies and export the data in different ways to various destinations.
Lakehouse & Data Warehouse:
The reason for including the Lakehouse and Data Warehouse is for that deeper analysis or further use of analytics that fall outside of the scope of the Real-Time Analytics reporting. The benefits of this are a solution that provides you with Real-Time Analytics and the historical retention of the data to be used in other analytical reporting.
One Logical Copy (Preview) allows you to interact with the data from the KQL Database in OneLake, which allows you to work with the data without physically copying it for different compute engines. Provides the ability of the lakehouse or Data Warehouse to use a shortcut to connect to the data in KQL without physically copying it to a lakehouse.
Now if you want to load that data into different files or warehouses for historical retention or other reasons, you would be physically moving/copying the data. This can be accomplished via Pipelines, Dataflows, Spark Notebooks, and even cross database query functionality between the Lakehouse, Datawarehouse, and KQL database when enabling the one logical copy in KQL (allows you to create a shortcut).
If you are using the KQL database as a source of data for your data warehouse or lakehouse, review the above architectures for guidelines when implementing these solutions.
Expose:
Power BI:
Users/teams will consume data through Power BI via reports, datasets, dashboards, apps, etc. That are sourced from the gold warehouse or tables.
When you enable ‘One Logical Copy’ then you will be able to use Direct lake mode.
Direct Lake Mode is a new semantic model capability for parquet formatted files to load directly from the data lake without having to query a warehouse endpoint OR import/duplicate data within the Power BI model. Learn about Direct Lake in Power BI and Microsoft Fabric – Power BI | Microsoft Learn
Otherwise, you will have to use import mode or direct query mode.
KQL Queryset:
The KQL Queryset is the item used to run queries, view, and customize query results on data from a KQL database.
Uses KQL for creating queries, views, functions, control commands, customized results and many SQL functions.
There are tabs in a KQL Queryset that allow you to connect/associate with different KQL Databases and switch them out to run the same query in different states.
You can collaborate with others and save queries.
Notebooks:
You can also explore data using Notebooks via Spark/KQL.
This allows you the ability to ingest, analyze, use in Machine Learning, or any of your processes via Notebooks directly from the KQL Database.
Conclusion
When thinking about creating new solutions, or migrating existing ones, within Fabric, understanding the capabilities of the Fabric components and your solution requirements are critical. By examining different use cases for the Data Warehouse, Lakehouse, and Real-Time Analytics/KQL Database, examples of different architecture patterns, and deep diving into the capabilities of each the Data Warehouse, Lakehouse, and Real-Time Analytics/KQL Database, there should be a clearer architecture design path when combined with the knowledge of your user/workload requirements.
Sources for article:
What is OneLake? – Microsoft Fabric | Microsoft Learn
What is a lakehouse? – Microsoft Fabric | Microsoft Learn
What is data warehousing in Microsoft Fabric? – Microsoft Fabric | Microsoft Learn
Fabric decision guide – choose a data store – Microsoft Fabric | Microsoft Learn
Tutorial: Ingest data into a lakehouse – Microsoft Fabric | Microsoft Learn
Fabric decision guide – copy activity, dataflow, or Spark – Microsoft Fabric | Microsoft Learn
OneLake shortcuts – Microsoft Fabric | Microsoft Learn
Implement medallion lakehouse architecture in Microsoft Fabric – Microsoft Fabric | Microsoft Learn
Overview of Real-Time Analytics – Microsoft Fabric | Microsoft Learn
Differences between Real-Time Analytics and Azure Data Explorer – Microsoft Fabric | Microsoft Learn
Fabric Change the Game: Real – time Analytics | Microsoft Fabric Blog | Microsoft Fabric

